Thanks to Gil Allouche (Qubole's VP of Marketing) for this post.
Hadoop and its ecosystem has evolved from a narrow map-reduced architecture to a universal data platform set to dominate the data processing landscape in the future. Importantly, the push to simplify Hadoop deployments with managed cloud services known as Hadoop-as-a-Service is increasing Hadoop’s appeal to new data projects and architectures. Naturally, the development is permeating the Hadoop ecosystem in shape of Pig as a Service offerings, for example.
Pig, developed by Yahoo research in 2006, enables programmers to write data transformation programs for Hadoop quickly and easily without the cost and complexity of map-reduce programs. Consequently, ETL (Extract, Transform, Load), the core workload of DWH (data warehouse) solutions, is often realized with Pig in the Hadoop environment. The business case for Hadoop and Pig as a Service is very compelling from financial and technical perspectives.
Hadoop is becoming data’s Swiss Army knife
The news on Hadoop last year have been dominated by SQL (Structured Query language) on Hadoop with Hive, Presto, Impala, Drill, and countless other flavours competing on making big data accessible to business users. Most of these solutions are supported directly by Hadoop distributors, e.g. Hortonworks, MapR, Cloudera, and cloud service providers, e.g. Amazon and Qubole.
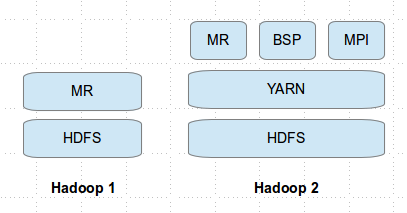
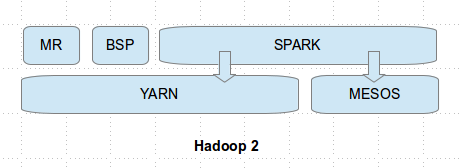
The push for development in the area is driven by the vision for Hadoop to become the data platform of the future. The release of Hadoop 2.0 with YARN (Yet Another Resource Negotiator) last year was an important step. It turned the core of Hadoop’s processing architecture from a map-reduce centric solution into a generic cluster resource management tool able to run any kind of algorithm and application. Hadoop solution providers are now racing to capture the market for multipurpose, any-size data processing. SQL on Hadoop is only one of the stepping-stones to this goal.
Hadoop and its ecosystem has evolved from a narrow map-reduced architecture to a universal data platform set to dominate the data processing landscape in the future. Importantly, the push to simplify Hadoop deployments with managed cloud services known as Hadoop-as-a-Service is increasing Hadoop’s appeal to new data projects and architectures. Naturally, the development is permeating the Hadoop ecosystem in shape of Pig as a Service offerings, for example.
Pig, developed by Yahoo research in 2006, enables programmers to write data transformation programs for Hadoop quickly and easily without the cost and complexity of map-reduce programs. Consequently, ETL (Extract, Transform, Load), the core workload of DWH (data warehouse) solutions, is often realized with Pig in the Hadoop environment. The business case for Hadoop and Pig as a Service is very compelling from financial and technical perspectives.
Hadoop is becoming data’s Swiss Army knife
The news on Hadoop last year have been dominated by SQL (Structured Query language) on Hadoop with Hive, Presto, Impala, Drill, and countless other flavours competing on making big data accessible to business users. Most of these solutions are supported directly by Hadoop distributors, e.g. Hortonworks, MapR, Cloudera, and cloud service providers, e.g. Amazon and Qubole.
The push for development in the area is driven by the vision for Hadoop to become the data platform of the future. The release of Hadoop 2.0 with YARN (Yet Another Resource Negotiator) last year was an important step. It turned the core of Hadoop’s processing architecture from a map-reduce centric solution into a generic cluster resource management tool able to run any kind of algorithm and application. Hadoop solution providers are now racing to capture the market for multipurpose, any-size data processing. SQL on Hadoop is only one of the stepping-stones to this goal.