There had been a lot of traction around Spark. Cloudera announced (1, 2) it being a part of the CDH distribution and here is there stance on `MR and Spark`. MapReduce is a programming model for distribution computing while Spark is a framework or a Software. The essence of the Cloudera article is accurate, but the blog title is a bit misleading. It should be Hadoop and Spark.
Here is another interesting article from Cloudera on Spark from a Data Science perspective. Mahout implements Machine Learning algorithms in a MR fashion. But, MR is batch oriented (high latency and high throughput) in nature and doesn't suit well for Machine Learning algorithms which are iterative in nature. There is a active discussion in the Mahout community for decoupling the ML algorithms from MR where possible. It is a long shot, but the sooner the effort the better as alternate distributed ML frameworks are cropping.
With Spark becoming a top level project and lot of attention to Spark, one might think what will happen to Hadoop that Spark is gaining all the attention. So, this blog is all about it.
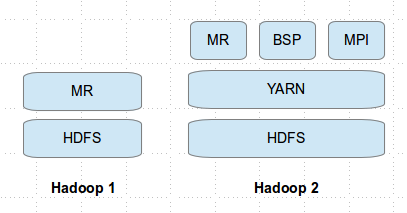 But, before jumping into Spark, let's look at how Hadoop has evolved. Hadoop 1 has two components HDFS (for storing the data at large scale) and MR (for processing the data at large scale) which operate on a group of commodity machines and act like a single cluster (or an entity) to work on a very big task. In Hadoop 2 (aka YARN, Next Generation Architecture, MRv2), Hadoop additionally constitutes YARN which has a centralized Resource Manager which allows multiple computing models (powered by YARN) to run on the same cluster. Executing multiple models on the same cluster will increase the utilization of the cluster and mostly flatten the usage of cluster.
But, before jumping into Spark, let's look at how Hadoop has evolved. Hadoop 1 has two components HDFS (for storing the data at large scale) and MR (for processing the data at large scale) which operate on a group of commodity machines and act like a single cluster (or an entity) to work on a very big task. In Hadoop 2 (aka YARN, Next Generation Architecture, MRv2), Hadoop additionally constitutes YARN which has a centralized Resource Manager which allows multiple computing models (powered by YARN) to run on the same cluster. Executing multiple models on the same cluster will increase the utilization of the cluster and mostly flatten the usage of cluster.
Along, the same lines Spark applications can also run a resource/cluster management framework like YARN and Apache Mesos. So, it's not a matter of making a choice between Spark and Hadoop, but Spark can run on top of YARN (Hadoop 2) and can also use HDFS as a source for data. More on the different Spark execution models from the official documentation here.
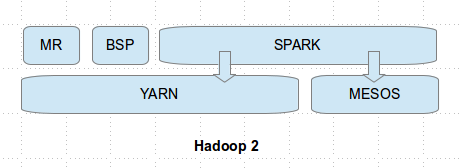 With so much traction happening around Spark, it's interesting to see how work loads gets moved from some of the other frameworks like Hadoop (MR) to Spark. Note that MR is a distributing computing model and can be implemented on a distributed computing model like Spark. Here is a simple Scala program for WordCount on top of Spark.
With so much traction happening around Spark, it's interesting to see how work loads gets moved from some of the other frameworks like Hadoop (MR) to Spark. Note that MR is a distributing computing model and can be implemented on a distributed computing model like Spark. Here is a simple Scala program for WordCount on top of Spark.
Here is another interesting article from Cloudera on Spark from a Data Science perspective. Mahout implements Machine Learning algorithms in a MR fashion. But, MR is batch oriented (high latency and high throughput) in nature and doesn't suit well for Machine Learning algorithms which are iterative in nature. There is a active discussion in the Mahout community for decoupling the ML algorithms from MR where possible. It is a long shot, but the sooner the effort the better as alternate distributed ML frameworks are cropping.
With Spark becoming a top level project and lot of attention to Spark, one might think what will happen to Hadoop that Spark is gaining all the attention. So, this blog is all about it.
Along, the same lines Spark applications can also run a resource/cluster management framework like YARN and Apache Mesos. So, it's not a matter of making a choice between Spark and Hadoop, but Spark can run on top of YARN (Hadoop 2) and can also use HDFS as a source for data. More on the different Spark execution models from the official documentation here.
file = spark.textFile("hdfs://...")
file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
With so much happening in the Big Data space, I will try to keep this blog updated with some of the latest happenings.
No comments:
Post a Comment