Note : Also don't forget to do check another entry on how to unit test MR programs with MRUnit here. And here is a screencast for the same.
Distributed applications are by nature difficult to debug, Hadoop is no exception. This blog entry will try to explain how to put break points and debug a user defined Java MapReduce program in Eclipse.
Hadoop support executing a MapReduce job in Standalone, Pseudo-Distributed and Fully-Distributed Mode. As we move from one more to another in the same order, the debugging becomes harder and new bugs are found on the way. Standalone mode with the default Hadoop configuration properties allows MapReduce programs to be debugged in Eclipse.

Step 1: Create a Java Project in Eclipse.


Step 2: For the Java project created in the earlier step, add the following dependencies (commons-configuration-1.6.jar, commons-httpclient-3.0.1.jar, commons-lang-2.4.jar, commons-logging-1.1.1.jar, commons-logging-api-1.0.4.jar, hadoop-core-1.0.3.jar, jackson-core-asl-1.8.8.jar, jackson-mapper-asl-1.8.8.jar and log4j-1.2.15.jar) in Eclipse. The dependencies are available by downloading and extracting a Hadoop release.

Step 3: Copy the MaxTemperature.java, MaxTemperatureMapper.java, MaxTemperatureReducer.java, MaxTemperatureWithCombiner.java, NewMaxTemperature.java to the src folder under the project. The Sample.txt file which contains the input data should be copied to the input folder. The project folder structure should look like below, without any compilation errors.

Step 4: Add the input and the output folder as the arguments to the MaxTemperature.java program.

Step 5: Execute MaxTemepature.java from Eclipse. There should be no exceptions/errors shown in the console. And on refreshing the project, an output folder should appear as should below on successful completion of the MapReduce job. To rerun the program, the output folder has to be deleted.

Step 6: As in the case of any Java program, break points can be put in the MapReduce driver, mapper, reducer code and debugged.

In the upcoming blog, we will see how to include/compile/debug Hadoop code into Eclipse along with the user defined driver, mapper and the reducer code.
Happy Hadooping !!!!
Note (5th March, 2013) : The above instructions have been tried on Ubuntu 12.04 which has all the utilities like chmod and others, which Hadoop uses internally. These tools are not available by default in Windows and you might get error as mentioned in this thread, when trying the steps mentioned in this blog on a Windows machine.
One alternative it to install Cygwin on Windows as mentioned in this tutorial. This might or might not work smoothly.
Microsoft is working very aggressively to port Hadoop to the Windows platform and has released HDInsight recently. Check this and this for more details. This is the best bet for all the Windows fans. Download the HDInsight Server on a Windows machine and try out Hadoop.
Distributed applications are by nature difficult to debug, Hadoop is no exception. This blog entry will try to explain how to put break points and debug a user defined Java MapReduce program in Eclipse.
Hadoop support executing a MapReduce job in Standalone, Pseudo-Distributed and Fully-Distributed Mode. As we move from one more to another in the same order, the debugging becomes harder and new bugs are found on the way. Standalone mode with the default Hadoop configuration properties allows MapReduce programs to be debugged in Eclipse.

Step 1: Create a Java Project in Eclipse.
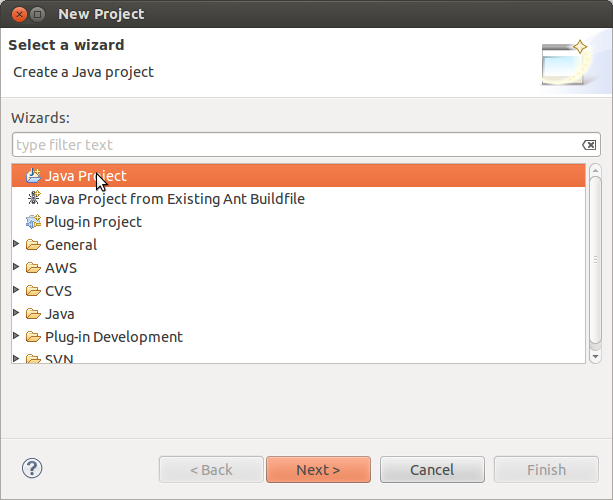

Step 2: For the Java project created in the earlier step, add the following dependencies (commons-configuration-1.6.jar, commons-httpclient-3.0.1.jar, commons-lang-2.4.jar, commons-logging-1.1.1.jar, commons-logging-api-1.0.4.jar, hadoop-core-1.0.3.jar, jackson-core-asl-1.8.8.jar, jackson-mapper-asl-1.8.8.jar and log4j-1.2.15.jar) in Eclipse. The dependencies are available by downloading and extracting a Hadoop release.

Step 3: Copy the MaxTemperature.java, MaxTemperatureMapper.java, MaxTemperatureReducer.java, MaxTemperatureWithCombiner.java, NewMaxTemperature.java to the src folder under the project. The Sample.txt file which contains the input data should be copied to the input folder. The project folder structure should look like below, without any compilation errors.

Step 4: Add the input and the output folder as the arguments to the MaxTemperature.java program.

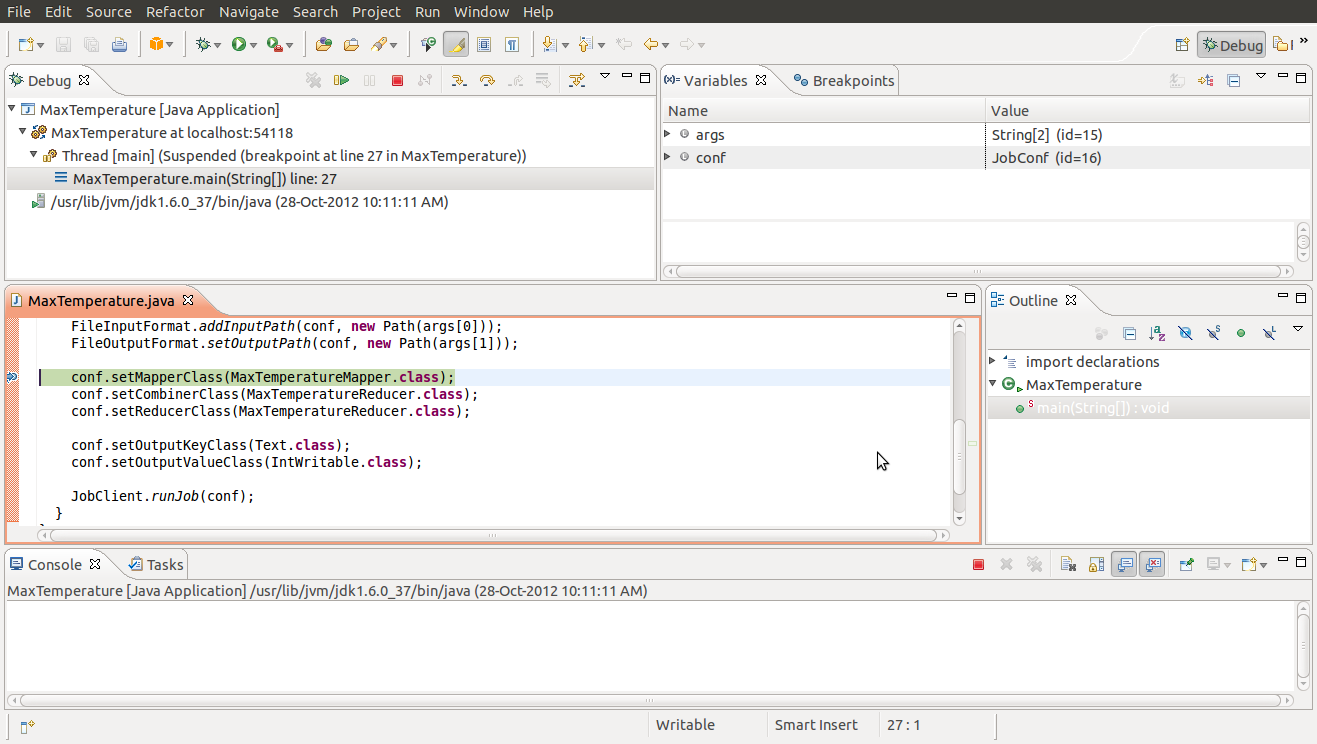
Step 5: Execute MaxTemepature.java from Eclipse. There should be no exceptions/errors shown in the console. And on refreshing the project, an output folder should appear as should below on successful completion of the MapReduce job. To rerun the program, the output folder has to be deleted.

Step 6: As in the case of any Java program, break points can be put in the MapReduce driver, mapper, reducer code and debugged.
In the upcoming blog, we will see how to include/compile/debug Hadoop code into Eclipse along with the user defined driver, mapper and the reducer code.
Happy Hadooping !!!!
Note (5th March, 2013) : The above instructions have been tried on Ubuntu 12.04 which has all the utilities like chmod and others, which Hadoop uses internally. These tools are not available by default in Windows and you might get error as mentioned in this thread, when trying the steps mentioned in this blog on a Windows machine.
One alternative it to install Cygwin on Windows as mentioned in this tutorial. This might or might not work smoothly.
Microsoft is working very aggressively to port Hadoop to the Windows platform and has released HDInsight recently. Check this and this for more details. This is the best bet for all the Windows fans. Download the HDInsight Server on a Windows machine and try out Hadoop.