Note : Also don't forget to do check another entry on how to get some interesting facts from Twitter using R here. And also this entry on how to use Oozie for automating the below workflow. Here is a new blog on how to do the same analytics with Pig (using elephant-bird).
It's not a hard rule, but almost 80% of the data is unstructured, while the remaining 20% is structured data. RDBMS helps to store/process the structured data (20%), while Hadoop solves the problem of storing/processing both types of data. The good thing about Hadoop, is that it scales incrementally with less CAPEX in terms of software and hardware.
With the ever increasing usage of smart devices and the high speeds internet, unstructured data had been growing at a very fast rate. It's common to Tweet from a smart phone, take a picture and share it in Facebook.
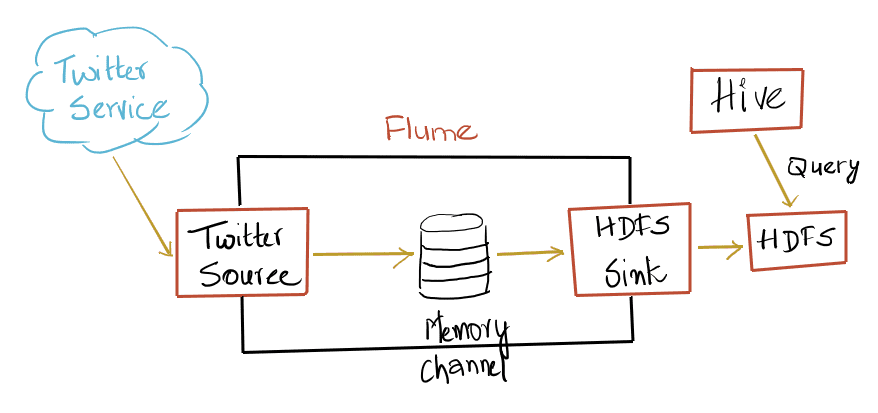
In this blog we will try to get Tweets using Flume and save them into HDFS for later analysis. Twitter exposes the API (more here) to get the Tweets. The service is free, but requires the user to register for the service. Cloudera wrote a three part series (1, 2, 3) for Twitter Analysis using Hadoop, the code for the same is here. For the impatient, I will quickly summarize how to get data into HDFS using Flume and start doing some analytics using Hive.
Flume has the concepts of agents. The sources, sinks and the intermediate channels are the different types of agents. The sources can push/pull the data and send it to the different channels which in turn will send the data to the different sinks. Flume decouples the source (Twitter) and the sink (HDFS) in this case. Both the source and the sink can operate at different speeds, also it's much easier to add new sources and sinks. Flume comes with a set of sources, channels, sinks and new onces can be implemented by extending the Flume base classes.

1) The first step is to create an application in https://dev.twitter.com/apps/ and then generate the corresponding keys.

2) Assuming that Hadoop has already been installed and configured, the next step is download Flume and extract it to any folder.
3) Download the flume-sources-1.0-SNAPSHOT.jar and add it to the flume class path as shown below in the conf/flume-env.sh file
4) The conf/flume.conf should have all the agents (flume, memory and hdfs) defined as below
The TwitterAgent.sources.Twitter.keywords value can be modified to get the tweets for some other topic like football, movies etc.
5) Start flume using the below command

6) Next download and extract Hive. Modify the conf/hive-site.xml to include the locations of the NameNode and the JobTracker as below
8) Start the Hive shell using the hive command and register the hive-serdes-1.0-SNAPSHOT.jar file downloaded earlier.
One of the way to determine who is the most influential person in a particular field is to to figure out whose tweets are re-tweeted the most. Give enough time for Flume to collect Tweets from Twitter to HDFS and then run the below query in Hive to determine the most influential person.
Happy Hadooping !!!
Edit (21st March, 2013) : Hortonworks blogged a two part series (1 and 2) on Twitter data processing using Hive.
Edit (30th March, 2016) : With the latest version of Flume, the following error is thrown because of the conflicts in the libraries
java.lang.NoSuchMethodError: twitter4j.FilterQuery.setIncludeEntities(Z)Ltwitter4j/FilterQuery;
at com.cloudera.flume.source.TwitterSource.start(TwitterSource.java:139)'
One solution is to remove the below libraries in the Flume lib folder. There are a couple of more solutions in this StackOverflow article.
It's not a hard rule, but almost 80% of the data is unstructured, while the remaining 20% is structured data. RDBMS helps to store/process the structured data (20%), while Hadoop solves the problem of storing/processing both types of data. The good thing about Hadoop, is that it scales incrementally with less CAPEX in terms of software and hardware.
With the ever increasing usage of smart devices and the high speeds internet, unstructured data had been growing at a very fast rate. It's common to Tweet from a smart phone, take a picture and share it in Facebook.
In this blog we will try to get Tweets using Flume and save them into HDFS for later analysis. Twitter exposes the API (more here) to get the Tweets. The service is free, but requires the user to register for the service. Cloudera wrote a three part series (1, 2, 3) for Twitter Analysis using Hadoop, the code for the same is here. For the impatient, I will quickly summarize how to get data into HDFS using Flume and start doing some analytics using Hive.
Flume has the concepts of agents. The sources, sinks and the intermediate channels are the different types of agents. The sources can push/pull the data and send it to the different channels which in turn will send the data to the different sinks. Flume decouples the source (Twitter) and the sink (HDFS) in this case. Both the source and the sink can operate at different speeds, also it's much easier to add new sources and sinks. Flume comes with a set of sources, channels, sinks and new onces can be implemented by extending the Flume base classes.
1) The first step is to create an application in https://dev.twitter.com/apps/ and then generate the corresponding keys.

2) Assuming that Hadoop has already been installed and configured, the next step is download Flume and extract it to any folder.
3) Download the flume-sources-1.0-SNAPSHOT.jar and add it to the flume class path as shown below in the conf/flume-env.sh file
FLUME_CLASSPATH="/home/training/Installations/apache-flume-1.3.1-bin/flume-sources-1.0-SNAPSHOT.jar"The jar contains the java classes to pull the Tweets and save them into HDFS.
4) The conf/flume.conf should have all the agents (flume, memory and hdfs) defined as below
TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS TwitterAgent.sources.Twitter.type = com.cloudera.flume.source.TwitterSource TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sources.Twitter.consumerKey = <consumerKey> TwitterAgent.sources.Twitter.consumerSecret = <consumerSecret> TwitterAgent.sources.Twitter.accessToken = <accessToken> TwitterAgent.sources.Twitter.accessTokenSecret = <accessTokenSecret> TwitterAgent.sources.Twitter.keywords = hadoop, big data, analytics, bigdata, cloudera, data science, data scientiest, business intelligence, mapreduce, data warehouse, data warehousing, mahout, hbase, nosql, newsql, businessintelligence, cloudcomputing TwitterAgent.sinks.HDFS.channel = MemChannel TwitterAgent.sinks.HDFS.type = hdfs TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/flume/tweets/ TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000 TwitterAgent.sinks.HDFS.hdfs.rollSize = 0 TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000 TwitterAgent.channels.MemChannel.type = memory TwitterAgent.channels.MemChannel.capacity = 10000 TwitterAgent.channels.MemChannel.transactionCapacity = 100The consumerKey, consumerSecret, accessToken and accessTokenSecret have to be replaced with those obtained from https://dev.twitter.com/apps. And, TwitterAgent.sinks.HDFS.hdfs.path should point to the NameNode and the location in HDFS where the tweets will go to.
The TwitterAgent.sources.Twitter.keywords value can be modified to get the tweets for some other topic like football, movies etc.
5) Start flume using the below command
bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n TwitterAgentAfter a couple of minutes the Tweets should appear in HDFS.

6) Next download and extract Hive. Modify the conf/hive-site.xml to include the locations of the NameNode and the JobTracker as below
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>7) Download hive-serdes-1.0-SNAPSHOT.jar to the lib directory in Hive. Twitter returns Tweets in the JSON format and this library will help Hive understand the JSON format.
8) Start the Hive shell using the hive command and register the hive-serdes-1.0-SNAPSHOT.jar file downloaded earlier.
ADD JAR /home/training/Installations/hive-0.9.0/lib/hive-serdes-1.0-SNAPSHOT.jar;9) Now, create the tweets table in Hive
CREATE EXTERNAL TABLE tweets (
id BIGINT,
created_at STRING,
source STRING,
favorited BOOLEAN,
retweet_count INT,
retweeted_status STRUCT<
text:STRING,
user:STRUCT<screen_name:STRING,name:STRING>>,
entities STRUCT<
urls:ARRAY<STRUCT<expanded_url:STRING>>,
user_mentions:ARRAY<STRUCT<screen_name:STRING,name:STRING>>,
hashtags:ARRAY<STRUCT<text:STRING>>>,
text STRING,
user STRUCT<
screen_name:STRING,
name:STRING,
friends_count:INT,
followers_count:INT,
statuses_count:INT,
verified:BOOLEAN,
utc_offset:INT,
time_zone:STRING>,
in_reply_to_screen_name STRING
)
ROW FORMAT SERDE 'com.cloudera.hive.serde.JSONSerDe'
LOCATION '/user/flume/tweets';
Now that we have the data in HDFS and the table created in Hive, lets run some queries in Hive.One of the way to determine who is the most influential person in a particular field is to to figure out whose tweets are re-tweeted the most. Give enough time for Flume to collect Tweets from Twitter to HDFS and then run the below query in Hive to determine the most influential person.
SELECT t.retweeted_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name as retweeted_screen_name, retweeted_status.text, max(retweet_count) as retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweeted_screen_name ORDER BY total_retweets DESC LIMIT 10;Similarly to know which user has the most number of followers, the below query helps.
select user.screen_name, user.followers_count c from tweets order by c desc;For sake of making it simple, partitions have not been created in Hive. Partitions can be created in Hive using Oozie at regular intervals to make the queries run faster if queried for a particular period time. Creating partitions will be covered in another blog.
Happy Hadooping !!!
Edit (21st March, 2013) : Hortonworks blogged a two part series (1 and 2) on Twitter data processing using Hive.
Edit (30th March, 2016) : With the latest version of Flume, the following error is thrown because of the conflicts in the libraries
java.lang.NoSuchMethodError: twitter4j.FilterQuery.setIncludeEntities(Z)Ltwitter4j/FilterQuery;
at com.cloudera.flume.source.TwitterSource.start(TwitterSource.java:139)'
One solution is to remove the below libraries in the Flume lib folder. There are a couple of more solutions in this StackOverflow article.
lib/twitter4j-core-3.0.3.jar
lib/twitter4j-media-support-3.0.3.jar
lib/twitter4j-stream-3.0.3.jar
