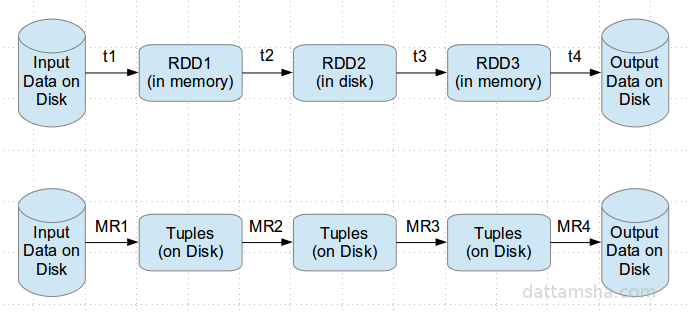
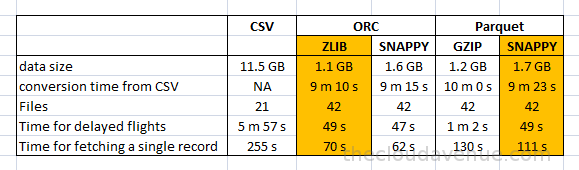
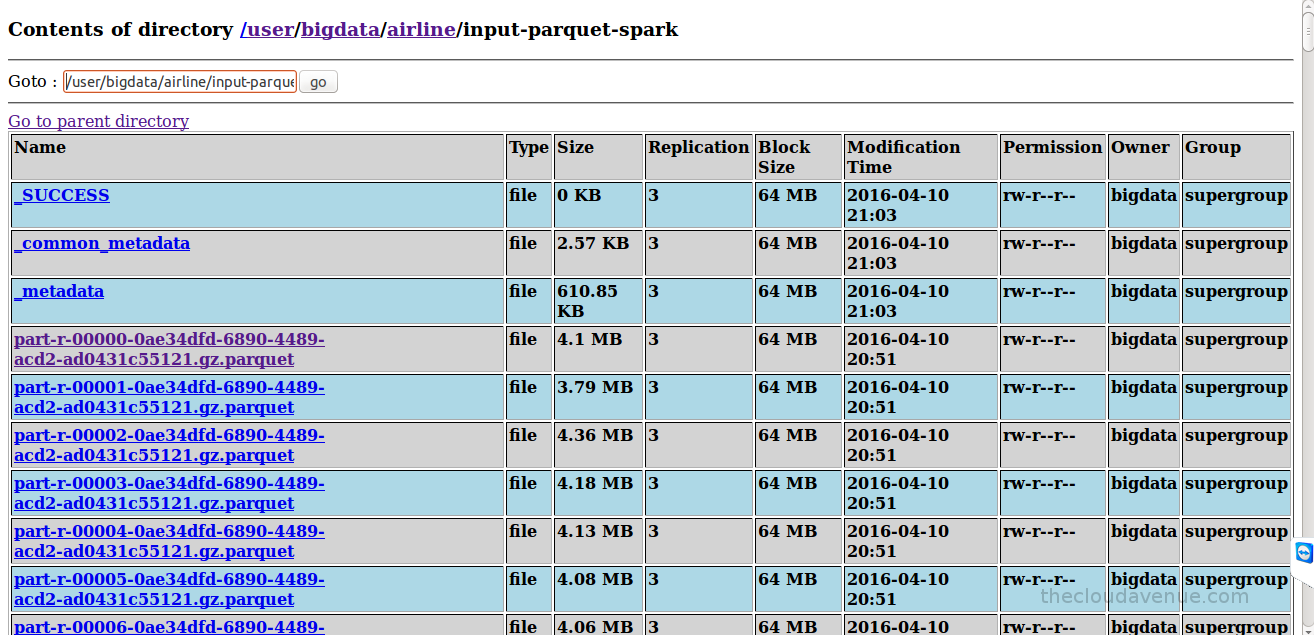
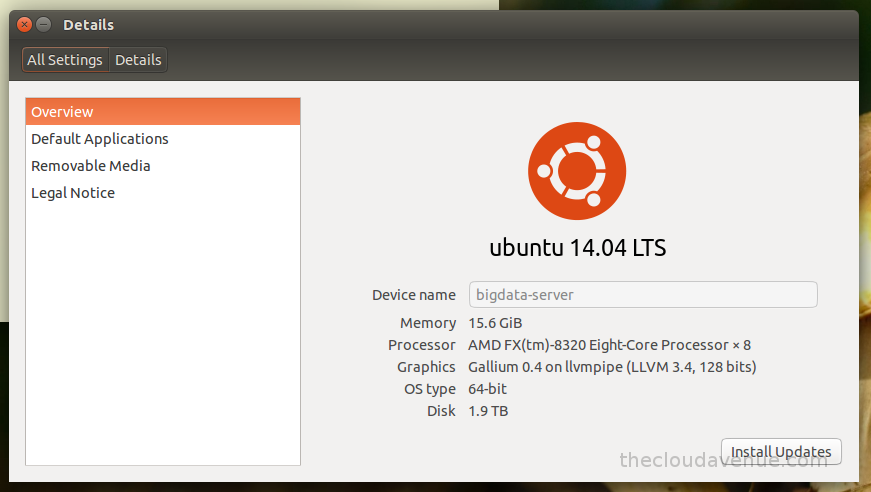
In the previous blog, we looked at how find out the maximum temperature of each year from the weather dataset. Below is the code for the same using Spark SQL which is a layer on top of Spark. SQL on Spark was supported using Shark which is being replaced by Spark SQL. Here is a nice blog from DataBricks on the future of SQL on Spark.
import re
import sys
from pyspark import SparkContext
from pyspark.sql import SQLContext, Row
#function to extract the data from the line
#based on position and filter out the invalid records
def extractData(line):
val = line.strip()
(year, temp, q) = (val[15:19], val[87:92], val[92:93])
if (temp != "+9999" and re.match("[01459]", q)):
return [(year, temp)]
else:
return []
logFile = "hdfs://localhost:9000/user/bigdatavm/input"
#Create Spark Context and SQL Context with the master details and the application name
sc = SparkContext("spark://bigdata-vm:7077", "max_temperature")
sqlContext = SQLContext(sc)
#Create an RDD from the input data in HDFS
weatherData = sc.textFile(logFile)
#Transform the data to extract/filter and then map it to a row
temperature_data = weatherData.flatMap(extractData).map(lambda p: Row(year=p[0], temperature=int(p[1])))
#Infer the schema, and register the SchemaRDD as a table.
temperature_data = sqlContext.inferSchema(temperature_data)
temperature_data.registerTempTable("temperature_data")
#SQL can be run over SchemaRDDs that have been registered as a table.
#Filtering can be done in the SQL using a where clause or in a py function as done in the extractData()
max_temperature_per_year = sqlContext.sql("SELECT year, MAX(temperature) FROM temperature_data GROUP BY year")
#Save the RDD back into HDFS
max_temperature_per_year.saveAsTextFile("hdfs://localhost:9000/user/bigdatavm/output")