PageRank is an iterative processing to find the relevancy of a web page in the world-wide-web. PageRank is one of the signal used by the search engine to figure out what to show at the top and what at the bottom of the search results. The `Data-Intensive Text Processing with MapReduce` has a very good description of what PageRank is and how to solve it in a MapReduce way.
As mentioned above PageRank is an iterative algorithm and MapReduce model is not good for iterative processing as the input and output of MapReduce in disk (from HDFS) which is really slow when compared to reading the data from the memory as in the case of Spark.
Anyway, working MapReduce code was available for the PageRank algorithm to process the Wiki data and so I thought of giving it shot. Here is the code and the description for the same. While iterating, if the difference between two iterations is small then the iterations are terminated. This logic is not implemented in the code.
Here is the data (english wiki) for the same. For those who don't have enough resources then a small wiki dump is also available for other languages.
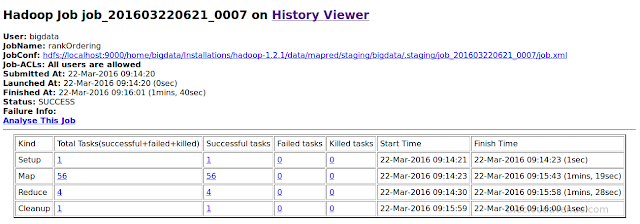
It took 7 minutes short of 3 hours to process 52.58 GB of enhlish wiki data. The processing included a total of 7 MR programs. The first one for parsing the wiki xml data, 5 iterations using MR to calculate the PageRank and the final MR program for ordering the wiki pages based on the ranking.
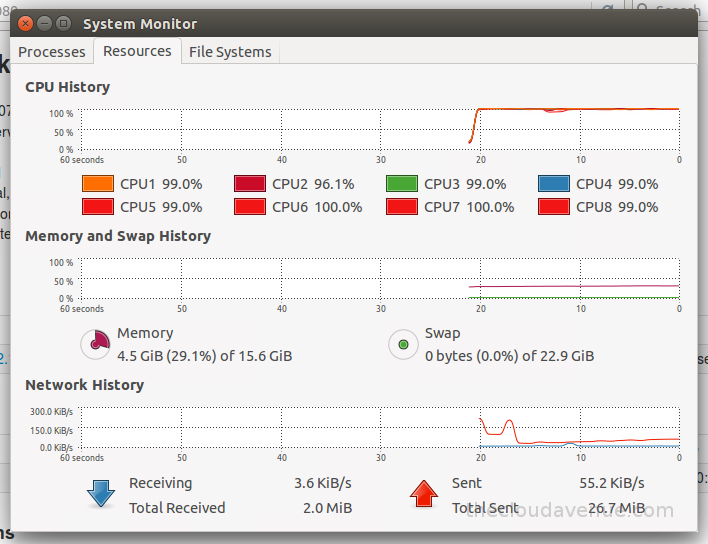
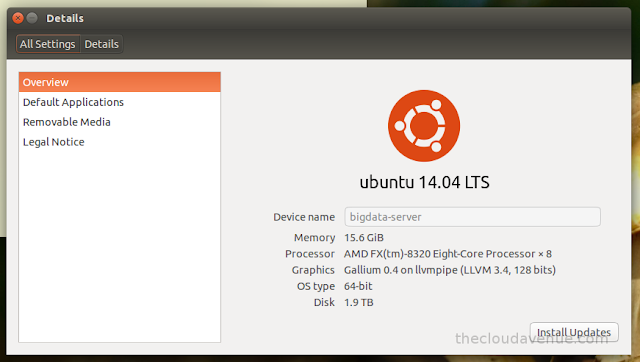
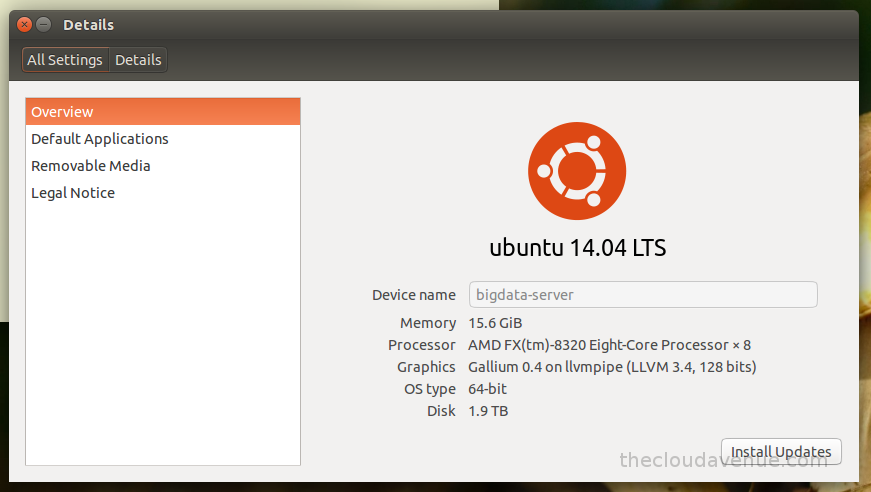
Here is the configuration of the machine on which the wiki data has been processed.
Here is the size of the input data.

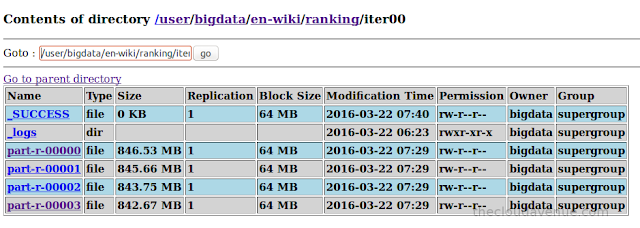
Here is the size of the data after the first MR program (parsing the wiki). Not that the size of the data got decreased significantly, as we only need the list of web pages, the web pages it has connected to and the initial page ranking to start the PageRank algorithm.
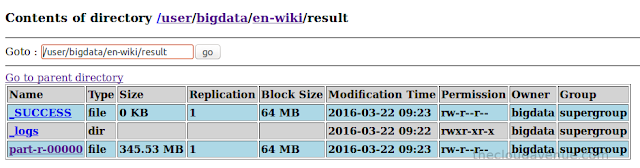
Here is the size of the final result, which is significantly small as only the webpage and the corresponding PageRank.
The file is a bit huge to open in gedit. So, head/tail is another way to look at the end of the file. Here is the screen for the same. Proud to see India in the top 10 list.

The rational behind publishing so many screen shots is for the readers to get the different metrics for the processing of the English wiki data. Your mileage might very depending on the configuration of the machine and the size of the input wiki data used for the processing.
As mentioned above PageRank is an iterative algorithm and MapReduce model is not good for iterative processing as the input and output of MapReduce in disk (from HDFS) which is really slow when compared to reading the data from the memory as in the case of Spark.
Anyway, working MapReduce code was available for the PageRank algorithm to process the Wiki data and so I thought of giving it shot. Here is the code and the description for the same. While iterating, if the difference between two iterations is small then the iterations are terminated. This logic is not implemented in the code.
Here is the data (english wiki) for the same. For those who don't have enough resources then a small wiki dump is also available for other languages.
It took 7 minutes short of 3 hours to process 52.58 GB of enhlish wiki data. The processing included a total of 7 MR programs. The first one for parsing the wiki xml data, 5 iterations using MR to calculate the PageRank and the final MR program for ordering the wiki pages based on the ranking.
Here is the configuration of the machine on which the wiki data has been processed.
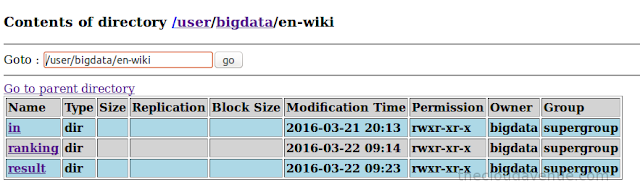
Here is the folder structure in HDFS.


Here is the size of the data after the first MR program (parsing the wiki). Not that the size of the data got decreased significantly, as we only need the list of web pages, the web pages it has connected to and the initial page ranking to start the PageRank algorithm.


The file is a bit huge to open in gedit. So, head/tail is another way to look at the end of the file. Here is the screen for the same. Proud to see India in the top 10 list.

Here is the screenshot of the MapReduce console with the 7 MapReduce programs.

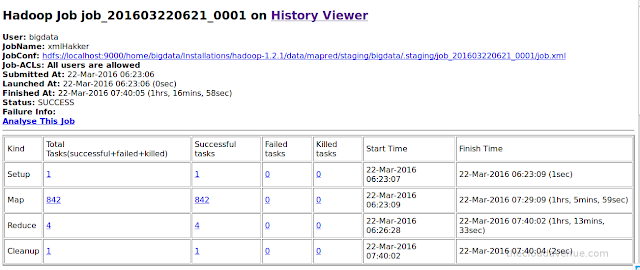
Here are the details of the first MapReduce program (xml parsing).

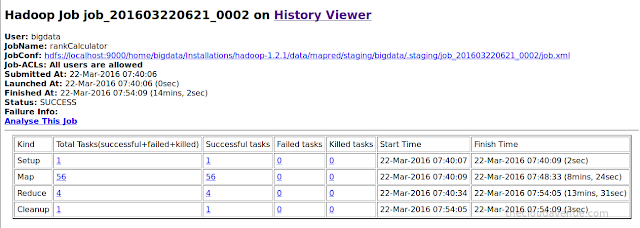
Here are the details of the MapReduce program implementing a single MapReduce iteration for calculating the PageRank.
Here are the details of the MapReduce program implementing the sorting based on the PageRank.
In the coming blogs, we will look into how to do the same think with Spark.