To process Big Data huge number of machines are required. Instead of buying them, it's better to process the data in the Cloud as it provides lower CAPEX and OPEX costs. In this blog we will at processing the
airline data set in the
AWS EMR (Elastic MapReduce). EMR provides Big Data as a service. We don't need to worry about installing, configuring, patching, security aspects of the Big Data software. EMR takes care of them, just we need specify the size and the number of the machines in the cluster, the location of the input/output data and finally the program to run. It's as easy as this.
The Airline dataset is in a csv format which is efficient for fetching the data in a row wise format based on some condition. But, not really efficient when we want to do some aggregations. So, we would be converting the CSV data into
Parquet format and then run the same queries on the csv and Parquet format to observe the performance improvements.
Note that using the AWS EMR will incur cost and doesn't fall under the AWS free tier as we would be launching not the t2.micro EC2 instances, but a bit bigger EC2 instances. I will try to keep the cost to the minimum as this is a demo. Also, I prepared the required scripts ahead and tested them in the local machine on small data sets instead of the AWS EMR. This will save the AWS expenses.
So, here are the steps
Step 1 : Download the Airline data set from
here and uncompress the same. All the data sets can be downloaded and uncompressed. But, to keep the cost to the minimum I downloaded the 1987, 1989, 1991, 1993 and 2007 related data and uploaded to S3 as shown below.
Step 2 : Create a folder called scripts and upload them to S3.
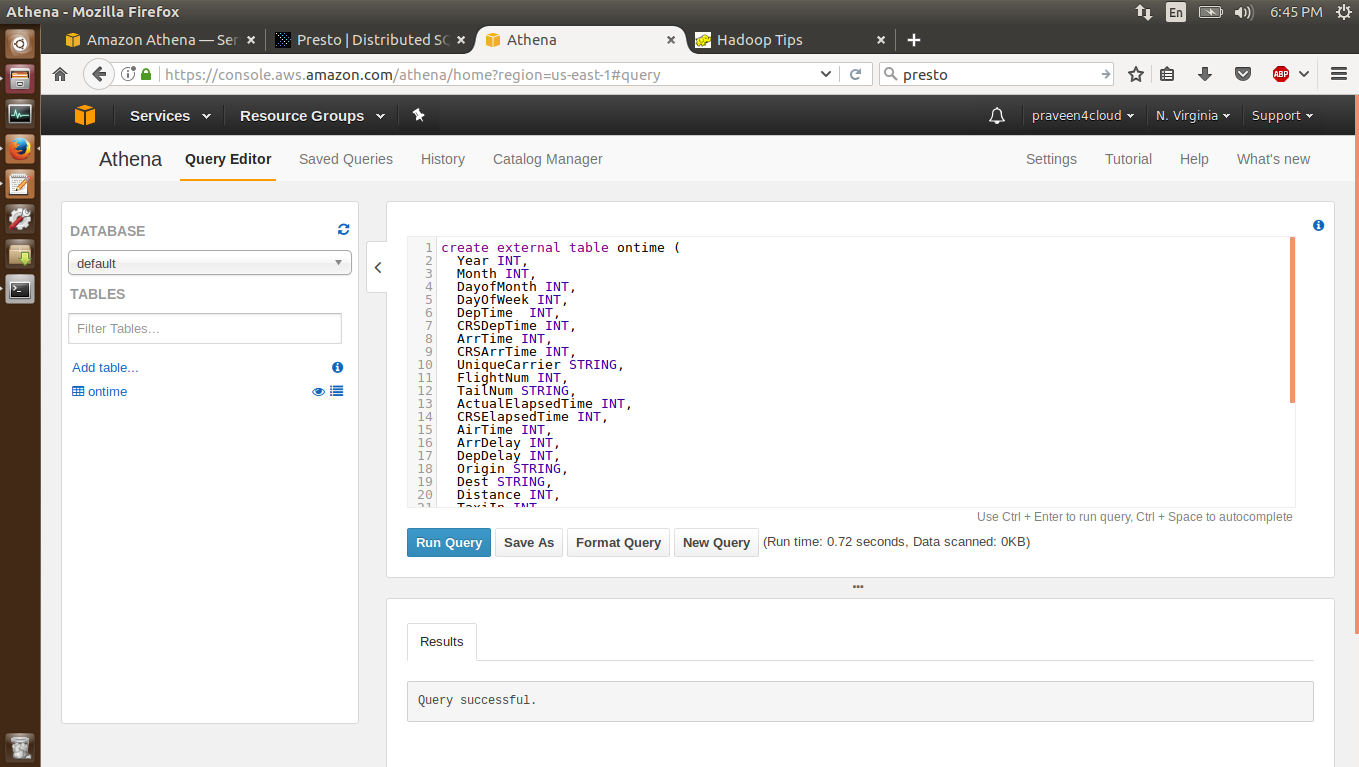
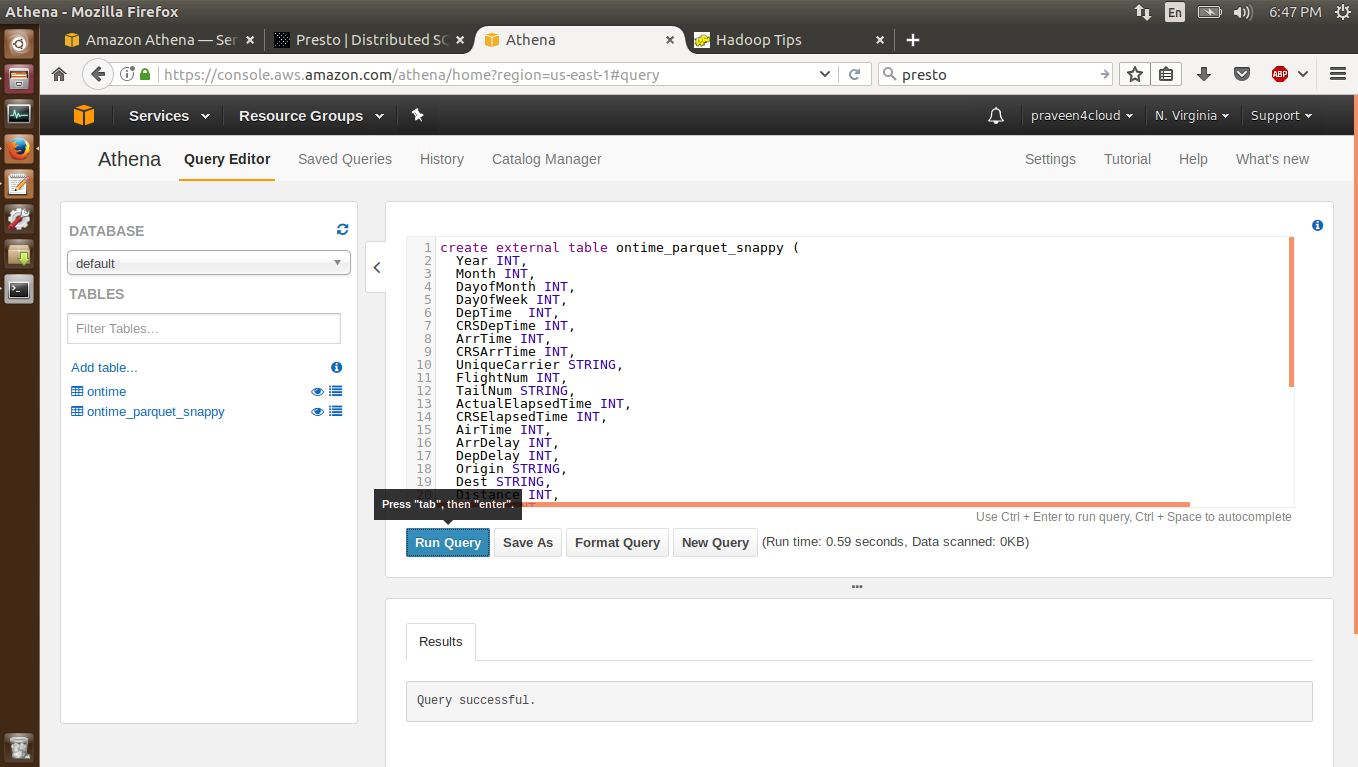
The '1-create-tables-move-data.sql' script will create the ontime and the ontime_parquet_snappy table, map the data to the table and finally move the data from the ontime table to the ontime_parquet_snappy table after transforming the data from the csv to the Parquet format. Below is the SQL for the same.
create external table ontime (
Year INT,
Month INT,
DayofMonth INT,
DayOfWeek INT,
DepTime INT,
CRSDepTime INT,
ArrTime INT,
CRSArrTime INT,
UniqueCarrier STRING,
FlightNum INT,
TailNum STRING,
ActualElapsedTime INT,
CRSElapsedTime INT,
AirTime INT,
ArrDelay INT,
DepDelay INT,
Origin STRING,
Dest STRING,
Distance INT,
TaxiIn INT,
TaxiOut INT,
Cancelled INT,
CancellationCode STRING,
Diverted STRING,
CarrierDelay INT,
WeatherDelay INT,
NASDelay INT,
SecurityDelay INT,
LateAircraftDelay INT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 's3://airline-dataset/airline-csv/';
create external table ontime_parquet_snappy (
Year INT,
Month INT,
DayofMonth INT,
DayOfWeek INT,
DepTime INT,
CRSDepTime INT,
ArrTime INT,
CRSArrTime INT,
UniqueCarrier STRING,
FlightNum INT,
TailNum STRING,
ActualElapsedTime INT,
CRSElapsedTime INT,
AirTime INT,
ArrDelay INT,
DepDelay INT,
Origin STRING,
Dest STRING,
Distance INT,
TaxiIn INT,
TaxiOut INT,
Cancelled INT,
CancellationCode STRING,
Diverted STRING,
CarrierDelay INT,
WeatherDelay INT,
NASDelay INT,
SecurityDelay INT,
LateAircraftDelay INT
) STORED AS PARQUET LOCATION 's3://airline-dataset/airline-parquet-snappy/' TBLPROPERTIES ("orc.compress"="SNAPPY");
INSERT OVERWRITE TABLE ontime_parquet_snappy SELECT * FROM ontime;
The '2-run-queries-csv.sql' script will run the query on the ontime table which maps to the csv data. Below is the query.
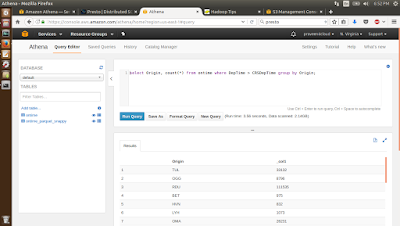
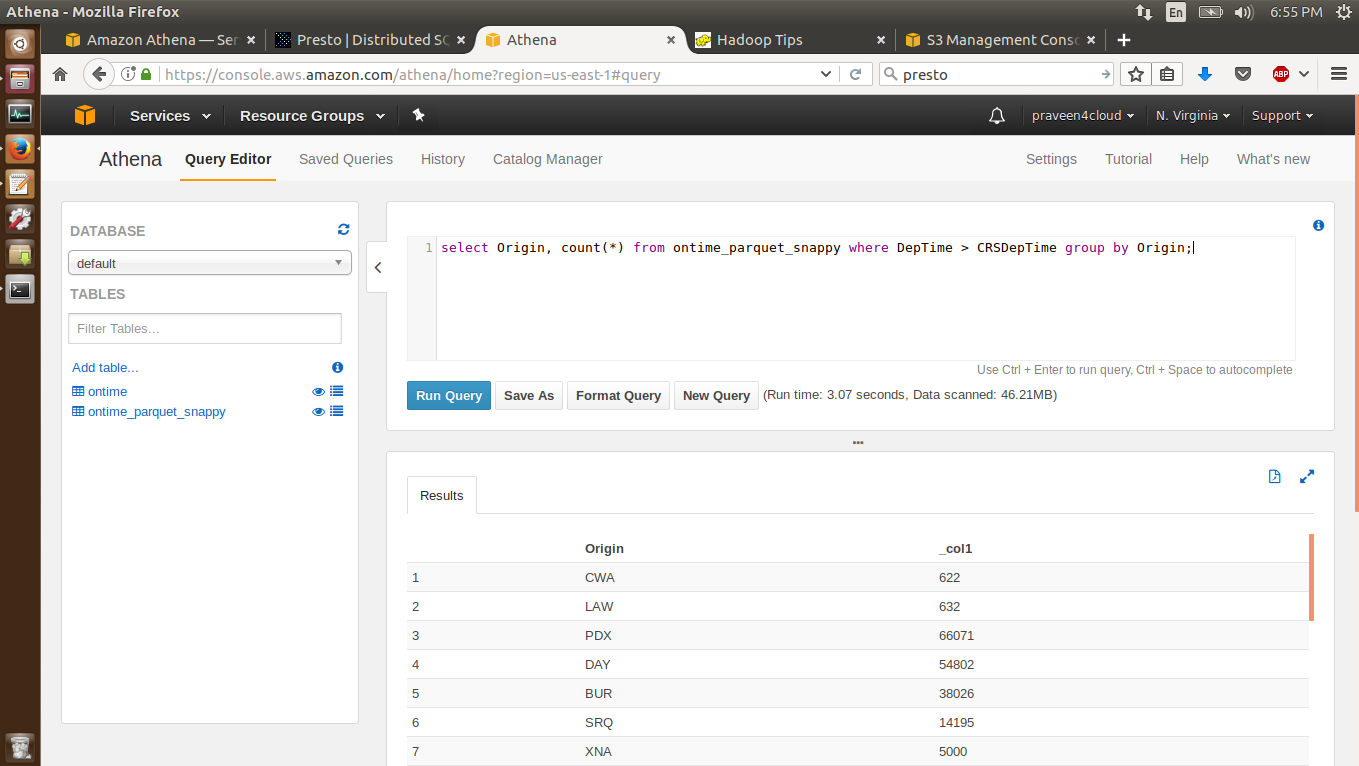
INSERT OVERWRITE DIRECTORY 's3://airline-dataset/csv-query-output' select Origin, count(*) from ontime where DepTime > CRSDepTime group by Origin;
The '3-run-queries-parquet.sql' script will run the query on the ontime_parquet_snappy table which maps to the Parquet-Snappy data. Below is the query.
INSERT OVERWRITE DIRECTORY 's3://airline-dataset/parquet-snappy-query-output' select Origin, count(*) from ontime_parquet_snappy where DepTime > CRSDepTime group by Origin;
Step 3 : Goto the EMR management console and click on the 'Go to advanced options'.
Step 4 : Here select the software to be installed on the instances. For this blog we need Hadoop 2.7.3 and Hive 2.1.1. Make sure these are selected, the rest are optional. Here we can add a step. According to the AWS
documentation, this is the definition of Step - 'Each step
is a unit of work that contains instructions to manipulate data for processing
by software installed on the cluster.'. This can be a MR program, Hive Query, Pig Script or something else. The steps can be added here or later. We will add steps later. Click on Next.
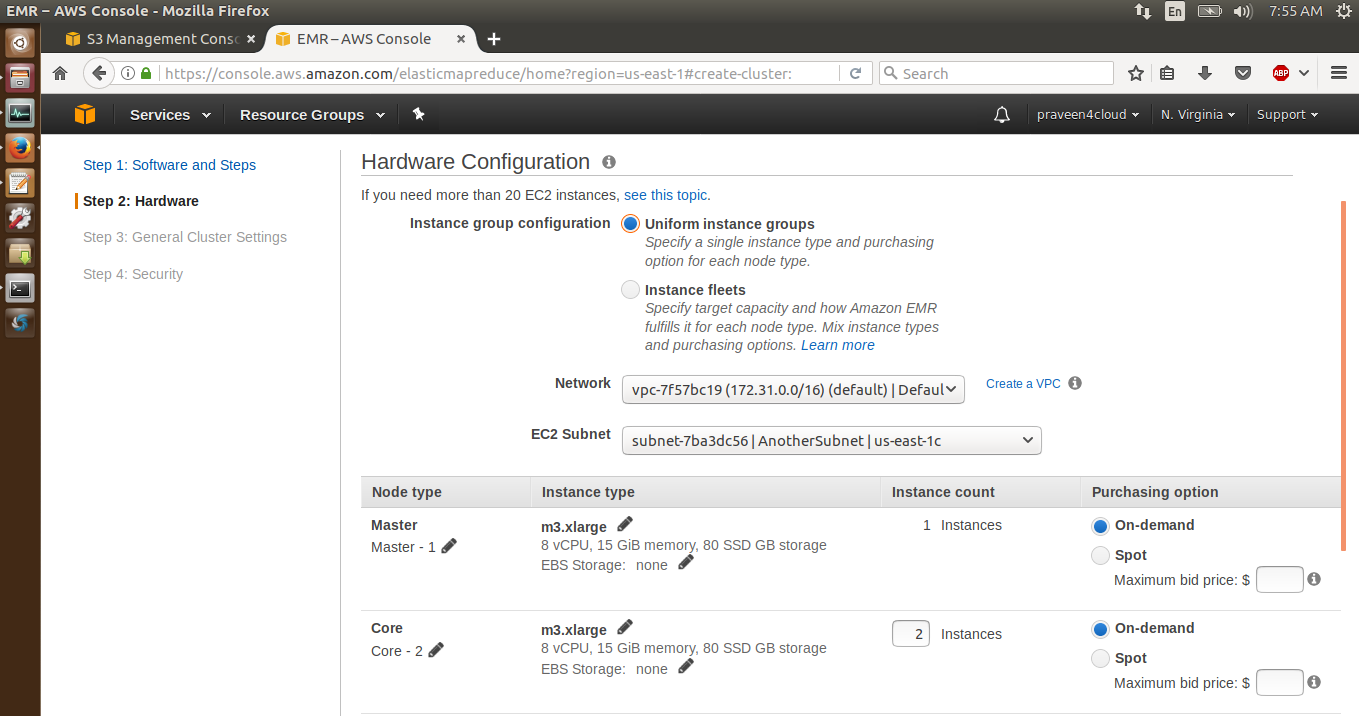
Step 5 : In this step, we can select the number of instances we want to run and the size of each instance. We will leave them as default and click on next.
Step 6 : In this step, we can select additional settings like the cluster name, the S3 log path location and so on. Make sure the 'S3 folder' points to the log folder in S3 and click on Next. Uncheck the 'Termination protection' option.
Step 7 : In this screen again all the default options are good enough. If we want to ssh into the EC2 instances then the 'EC2 key pair' has to be selected.
Here are the instructions on how to create a key pair. Finally click on 'Create cluster' to launch the cluster.
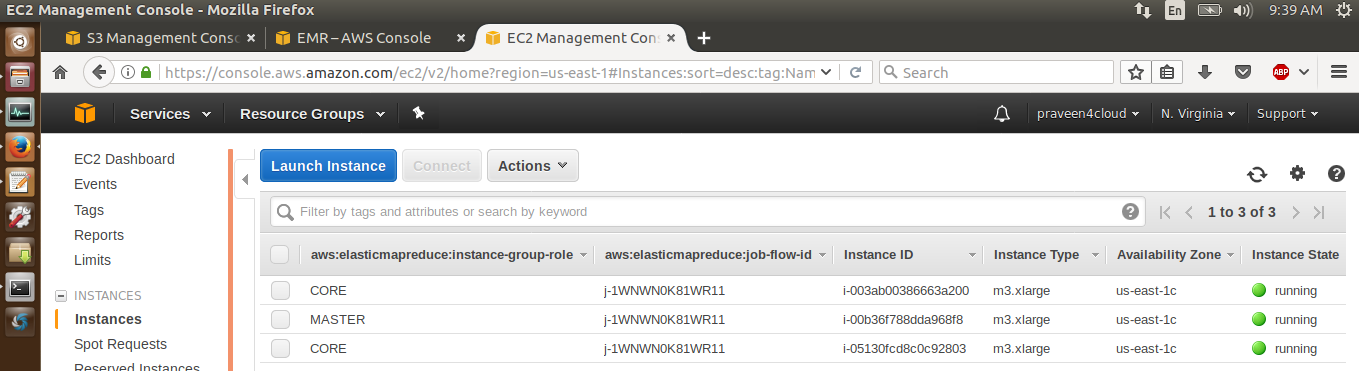
Initially the cluster will be in a Starting state and the EC2 instances will be launched as shown below.
Within a few minutes, the cluster will be in a running state and the Steps (data processing programs) can be added to the cluster.
Step 8 : Add a Step to the cluster by clicking on the 'Add step' and pointing to the '1-create-tables-move-data.sql' file as shown below and click on Add. The processing will start on the cluster.
The Step will be in a Pending status for some time and then move to the Completed status after the processing has been done.
Once the processing has been complete the csv data will be converted into a Parquet format with Snappy compression and put into S3 as shown below.
Note that the csv data was close to 2,192 MB and the Parquet Snappy data is around 190 MB. The Parquet data is in columnar format and provides higher compression compared to the csv format. This enables to fit more data into the memory and so quicker results.
Step 9 : Now add 2 more steps using the '2-run-queries-csv.sql' and the '3-run-queries-parquet.sql'. The first sql file will run the query on the csv data table and the second will run the query on the Parquet Snappy table. Both the queries are the same, returning the same results in S3.
Step 10 : Check the step log files for the steps to get the execution times in the EMR management console.
Converting the CSV to Parquet Snappy format - 148 seconds
Executing the query on the csv data - 90 seconds
Executing the query on the Parquet Snappy data - 56 seconds
Note that the query runs faster on the Parquet Snappy data, when compared to the csv data. I was expecting the query to run a bit faster, need to look into this a bit more.
Step 11 : Now that the processing has been done, it's time to terminate the cluster. Click on Terminate and again on Terminate. It will take a few minutes for the cluster to terminate.
Note that the EMR cluster will be terminated and EC2 instances will also terminate.
Step 12 : Go back to S3 management console the below folders should be there. Clean up by deleteing the bucket. I would be keeping the data, so that I can try Athena and RedShift on the CSV and the Parquet Snappy data. Note that 5GB of S3 data can be stored for free upto one year. More details about the AWS free tier
here.
In the future blogs, we will look at processing the same data using
AWS Athena. With Athena there is no need to spawn a cluster, so the serverless model. AWS Athena will automatically spawn the servers. We simply create a table, map it to the data in S3 and run the SQL queries on it.
With the EMR the pricing is rounded to the hour and for executing a query about 1 hour and 5 minutes, we need to pay for complete 2 hours. With Athena we pay by the amount of the data scanned. So, changing the data into a columnar format and compressing it, will not only make the query run a bit faster, but also cut down the bill.
Update :
Here and
here are articles from the AWS documentation on the same. It has got some additional commands.
Update :
Here is an approach using Spark/Python on EMR for converting the row format to Columnar format.