Thanks to
Vincent Danen for the picture. `A picture is worth a thousand words`. The book in the foreground is the 3rd edition of `Learning Python` and in the back is the
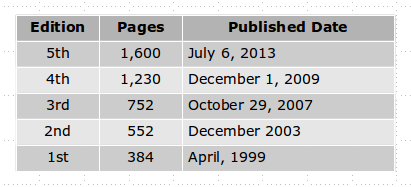
5th edition. The book had been getting thicker edition-by-edition. I did a quick look in Amazon and the below table gives the size of each edition and the published date. Maybe, we can use non-linear regression to figure out the size of the next edition :)
Kidding aside, the author (Mark Lutz) of
Learning Python - 5th edition does a very good job introducing Python and slowly moving into some of the advanced topics. But, the only gripe I have is that the book is huge (cannot be carried easily) and that the author repeats some of the topics again and again. So, if you are a quick reader like me, then you can quickly skip some of the repeated content and focus more time on the topics of interest.
For those who are into Python for some quick results, this book is certainly not an option. But, if you are into Python for a long haul for using it with Data Science or something else, then the book is worth the time. The book is about Python in general, so can be applied to other areas in Python (Scripting, Data Science, Dynamic Pages etc). The author also mentions the Python ecosystem at a very high level, so this book also gives a 360 view of Python.
Once familiar and comfortable with Python, the author also published
Python Pocket Reference and also
Programming Python (on how to develop applications in Python).