The Big Data revolution was started by the Google's Paper on MapReduce
(MR). But, the MR model mainly suits batch oriented processing of the
data and some of the other models are being shoe horned into it because of the
prevalence of Hadoop and the attention/support it gets. With the introduction of
YARN in Hadoop, other models besides MR could be first-class-citizens in the Hadoop space.
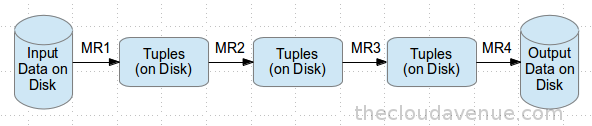
Lets take the case of MR as shown below, there is a lot of reading and writing happening to the disk after each MR transformation which makes is too slow and less suitable for iterative processing as in the case of Machine Learning.
 Let's see how we can solve the iterative problem with Apache Spark. Spark is built using Scala around the concept of Resilient Distributed Datasets (RDD) and provides actions / transformations on top of RDD. It has one of the best documentation around open source projects. There was not much resources around RDD, but this paper and presentation are the roots of RDD. Check this to know more about RDDs from a Spark perspective.
Let's see how we can solve the iterative problem with Apache Spark. Spark is built using Scala around the concept of Resilient Distributed Datasets (RDD) and provides actions / transformations on top of RDD. It has one of the best documentation around open source projects. There was not much resources around RDD, but this paper and presentation are the roots of RDD. Check this to know more about RDDs from a Spark perspective.
Let's look at a very high level what RDDs are and use this as a foundation to build upon Spark and other related frameworks in the upcoming blog articles. According to earlier mentioned paper
Formally, an RDD is a read-only, partitioned collection of records. RDDs can only be created through deterministic operations on either (1) data in stable storage or (2) other RDDs.
This is the holy grail of what an RDD is. RDDs are a 'immutable resilient distributed collection of records' which can be stored in the volatile memory or in a persistent storage (HDFS, HBase etc) and can be converted into another RDD through some of the transformations. An action like count can also be applied on an RDD.
 As observed in the above flow, the data flow from one iteration to another happens through memory and doesn't touch the disk (except for RDD2). When the memory is not sufficient enough for the data to fit it, it can be either spilled to the drive or is just left to be recreated upon request for the same.
As observed in the above flow, the data flow from one iteration to another happens through memory and doesn't touch the disk (except for RDD2). When the memory is not sufficient enough for the data to fit it, it can be either spilled to the drive or is just left to be recreated upon request for the same.
Because of the distributed nature of the Big Data processing, there is a better probability that a couple of nodes might go down at any point of time. Note that in the above flow, the RDD2 is persisted to disk because of Check Pointing. In the work flow, for any failure during the transformations t3 or t4, the entire work flow need not be played back because the RDD2 is persisted to disk. It would be enough if transformation t3 and t4 are played back.
Also, RDD can be cached in memory for frequently cached data. Lets say different queries are run on the same set of data again and again, this particular data can be kept in memory for better execution times.
To summarize, for iterative processing MR model is less suited than the RDD model. Performance metrics around iterative and other processings are mentioned in detail in this paper around RDD.
Lets take the case of MR as shown below, there is a lot of reading and writing happening to the disk after each MR transformation which makes is too slow and less suitable for iterative processing as in the case of Machine Learning.
Let's look at a very high level what RDDs are and use this as a foundation to build upon Spark and other related frameworks in the upcoming blog articles. According to earlier mentioned paper
Formally, an RDD is a read-only, partitioned collection of records. RDDs can only be created through deterministic operations on either (1) data in stable storage or (2) other RDDs.
This is the holy grail of what an RDD is. RDDs are a 'immutable resilient distributed collection of records' which can be stored in the volatile memory or in a persistent storage (HDFS, HBase etc) and can be converted into another RDD through some of the transformations. An action like count can also be applied on an RDD.
Because of the distributed nature of the Big Data processing, there is a better probability that a couple of nodes might go down at any point of time. Note that in the above flow, the RDD2 is persisted to disk because of Check Pointing. In the work flow, for any failure during the transformations t3 or t4, the entire work flow need not be played back because the RDD2 is persisted to disk. It would be enough if transformation t3 and t4 are played back.
Also, RDD can be cached in memory for frequently cached data. Lets say different queries are run on the same set of data again and again, this particular data can be kept in memory for better execution times.
To summarize, for iterative processing MR model is less suited than the RDD model. Performance metrics around iterative and other processings are mentioned in detail in this paper around RDD.
Good one on RDD.
ReplyDeleteBest one I have seen
ReplyDeletePretty nicely explained and good links.
ReplyDeleteNice article - informative and good links .. thanks
ReplyDeletewell explained - Thanks
ReplyDeleteLiked..Thanks
ReplyDeleteExcellent explanation! Pretty straight-forward. Couldn't thank enough.
ReplyDeleteKeep up the good work.
Thanks
Good Explanation
ReplyDeleteThank you...!