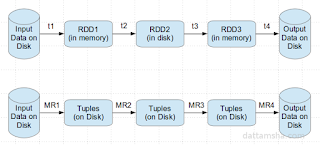
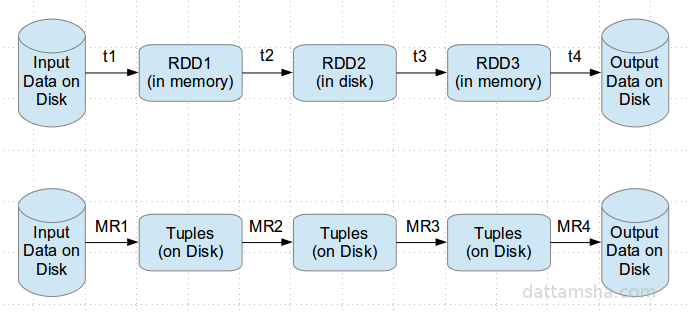
Apache Spark provides an efficient way for solving iterative algorithms by keeping the intermediate data in the memory. This avoids the overhead of R/W of the intermediate data from the disk as in the case of MR.
Also, when running the same operation again and again, data can be cached/fetched from the memory without performing the same operation again. MR is stateless, lets say a program/application in MR has been executed 10 times, then the whole data set has to be scanned 10 times.
 Also, namesake MR supports only Map and Reduce operations and everything (join, groupby etc) has to be fit into the Map and Reduce model, which might not be the efficient way. Spark supports a couple of other transformations and actions besides just Map and Reduce as mentioned here and here.
Also, namesake MR supports only Map and Reduce operations and everything (join, groupby etc) has to be fit into the Map and Reduce model, which might not be the efficient way. Spark supports a couple of other transformations and actions besides just Map and Reduce as mentioned here and here.
Spark code is also compact when compared to the MR code. Below is the program for performing the WordCount using Python in Spark.
Also, when running the same operation again and again, data can be cached/fetched from the memory without performing the same operation again. MR is stateless, lets say a program/application in MR has been executed 10 times, then the whole data set has to be scanned 10 times.
Spark code is also compact when compared to the MR code. Below is the program for performing the WordCount using Python in Spark.
from pyspark import SparkContext
logFile = "hdfs://localhost:9000/user/bigdatavm/input"
sc = SparkContext("spark://bigdata-vm:7077", "WordCount")
textFile = sc.textFile(logFile)
wordCounts = textFile.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)
wordCounts.saveAsTextFile("hdfs://localhost:9000/user/bigdatavm/output")
and the same in MR model using Hadoop is a bit verbose as shown below.
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<Intwritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Here we looked into WordCount which is similar to HelloWorld program in
terms of simplicity, for one to get started with a new
concept/technology/language. In the future blogs, we will look into a
little more advanced features in Spark.
No comments:
Post a Comment