CSV is the most familiar way of storing the data. In this blog I will try to compare the performance aspects of the ORC and the Parquet formats. There is a lot of literature on what these are, so less focus on the same.
Similar to Parquet for storing the data in the column oriented format there is another format called ORC. Parquet had been aggressively promoted by Cloudera and ORC by Hortonworks. Here are some articles (1, 2) on Parquet vs ORC.
The CSV data can be converted into ORC and Parquet formats using Hive. These are the steps involved. The same steps are applicable to ORC also. Simply, replace Parquet with ORC. Behind the scenes a MapReduce job will be run which will convert the CSV to the appropriate format.
- Create a Hive table (ontime)
- Map the ontime table to the CSV data
- Create a Hive table ontime_parquet and specify the format as Parquet
- Move the table from the ontime table to the ontime_parquet table
In the previous blog, we have seen how to convert CSV into Parquet using Hive. The procedure is more or less for ORC, just replace the `STORED AS PARQUET` to `STORED AS ORC` in the table definition as shown below and also specify the compressions codec to use.




Similar to Parquet for storing the data in the column oriented format there is another format called ORC. Parquet had been aggressively promoted by Cloudera and ORC by Hortonworks. Here are some articles (1, 2) on Parquet vs ORC.
The CSV data can be converted into ORC and Parquet formats using Hive. These are the steps involved. The same steps are applicable to ORC also. Simply, replace Parquet with ORC. Behind the scenes a MapReduce job will be run which will convert the CSV to the appropriate format.
- Create a Hive table (ontime)
- Map the ontime table to the CSV data
- Create a Hive table ontime_parquet and specify the format as Parquet
- Move the table from the ontime table to the ontime_parquet table
In the previous blog, we have seen how to convert CSV into Parquet using Hive. The procedure is more or less for ORC, just replace the `STORED AS PARQUET` to `STORED AS ORC` in the table definition as shown below and also specify the compressions codec to use.
create external table ontime_orc_snappy (
Year INT,
Month INT,
DayofMonth INT,
DayOfWeek INT,
DepTime INT,
CRSDepTime INT,
ArrTime INT,
CRSArrTime INT,
UniqueCarrier STRING,
FlightNum INT,
TailNum STRING,
ActualElapsedTime INT,
CRSElapsedTime INT,
AirTime INT,
ArrDelay INT,
DepDelay INT,
Origin STRING,
Dest STRING,
Distance INT,
TaxiIn INT,
TaxiOut INT,
Cancelled INT,
CancellationCode STRING,
Diverted STRING,
CarrierDelay INT,
WeatherDelay INT,
NASDelay INT,
SecurityDelay INT,
LateAircraftDelay INT
) STORED AS PARQUET LOCATION '/user/bigdata/airline/input-orc-snappy-from-hive' TBLPROPERTIES ("orc.compress"="SNAPPY");
Then the data has to be moved from the regular Hive table (ontime) to the ontime_orc_snappy using the below command.INSERT OVERWRITE TABLE ontime_parquet_gzip SELECT * FROM ontime;The property name for the and the default properties are mentioned in the below table. When not using the default compression codec then the property can be set on the table using the TBLPROPERTIES as shown in the above table creation command. Note that ZLIB in ORC and GZIP in Parquet uses the same compression codec, just the property name is different.

Four tables need to be created in Hive for the combination of orc/parquet and snappy/zlib/gzip compression as shown below.

Now that the tables have been created, the data can be moved from the ontime table to the remaining four tables. Four folders in HDFS will be created as shown below.
One the four tables I ran two queries on all the four tables. The first query was of type aggregation to find the number of delayed flights per origin as shown below.
select Origin, count(*) from ontime_parquet_gzip where DepTime > CRSDepTime group by Origin;The second query is to fetch all the columns in a single row as shown below.
select * from ontime_parquet_gzip where origin = 'LNY' and AirTime = 16;Below is the comparison matrix which is of main interest.
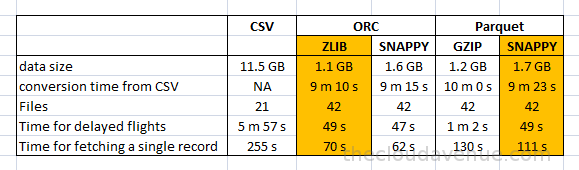
Here are a few things which I want to highlight
- There is not much of storage savings when using using ORC and Parquet when using the same compression code like `SNAPPY vs SNAPPY` and `ZLIB vs GZIP`.
- The time for converting from CSV to ORC and Parquet format is very close, not much difference considering the total time it takes for the conversion.
- Hortonworks blog says that the ORC format provides much better compression ratio when compared to Parquet. This is a bit misleading as the default properties are being used, ZLIB for ORC and SNAPPY for Parquet. By making sure that both the formats use the compression codec, there is not much significant difference in the compression ratio as shown in the above matrix. So, it would be better to focus on the features.
- For aggregation queries like `time for the the delayed flights` there is not such a drastic difference. Both the ORC and Parquet formats perform considerably well when compared to the CSV format.
- While fetching all the columns for a single now using a condition like "where origin = 'LNY' and AirTime = 16;", ORC has an edge over Parquet because the ORC format has a light index along with each file. By using the indexes in ORC, the underlying MapRedeuce or Spark can avoid reading the entire block.
- The indexing in Parquet seems to be a good differentiator. Although the ORC has to create Index while creating the files, there is not significant difference for the conversion and also the size of the files for both the formats.
- The different Big Data vendors try to promote their own format without worrying much about the interoperability. The Cloudera Certification has topics about Parquet, while the Hortonworks Certifications has topics around ORC.
This has been a lengthy blog than I expected, so bye for now and see you soon.
create table ontime_orc_snappy syntax having "STORED AS PARQUET LOCATION" instead of "ORC". Can you check that ?
ReplyDeleteThx!
ReplyDeleteIt should be: "By making sure that both the formats use the *same* compression codec..." right?
ReplyDelete