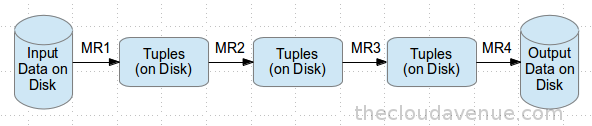
Bloom Filters allows to efficiently check if a particular element/record is there in the set/table or not. It has very minimal impact on the insert operations. The only caveat is that it might return a false positive, Bloom filter might say that a particular element/record is there in the set/table even when that particular item of interest is not there. Bloom Filters have been implemented in HBase and are by default enabled.
Interesting to know that Google Chrome browser used to implement Bloom Filters and has been later replaced with an alternate approach. According to Wikipedia (outdated):
The Google Chrome web browser uses a Bloom filter to identify malicious URLs. Any URL is first checked against a local Bloom filter and only upon a hit a full check of the URL is performed.
HBase implements Bloom filters on the server side, while Chrome implements the Bloom filter on the client/browser side. So, Bloom filter data is up to date in HBase, but might be a bit outdated in the Chrome browser. There are some variations of Bloom Filters, but the basic concept is very simple and beautiful.

Interesting to know that Google Chrome browser used to implement Bloom Filters and has been later replaced with an alternate approach. According to Wikipedia (outdated):
The Google Chrome web browser uses a Bloom filter to identify malicious URLs. Any URL is first checked against a local Bloom filter and only upon a hit a full check of the URL is performed.
HBase implements Bloom filters on the server side, while Chrome implements the Bloom filter on the client/browser side. So, Bloom filter data is up to date in HBase, but might be a bit outdated in the Chrome browser. There are some variations of Bloom Filters, but the basic concept is very simple and beautiful.