In K8S, everything is declarative and not imperative. We specify the target state to K8S and it will make sure that that the target state is always there, even in the case of failures. Basically, we specify what we want (as in the case of SQL) and not how to do it.
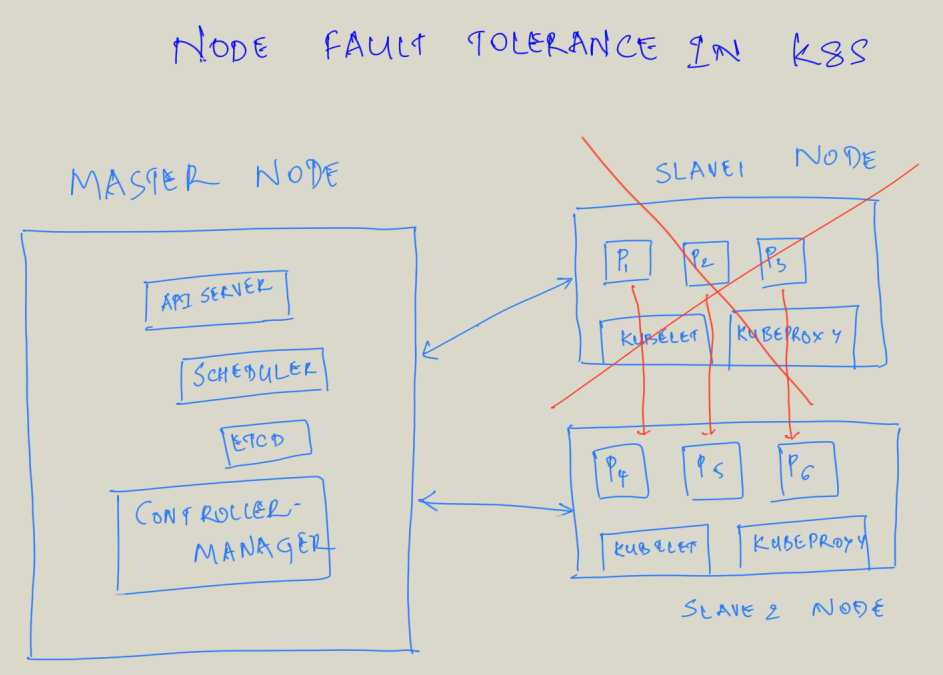
 In the above scenario, we have 1 master and 2 nodes. We can ask K8S to deploy 6 pods (application instances) onto the nodes and K8S will automatically schedule the pods across the nodes. In case one of the node goes down, then K8S will automatically reschedule the pods from the failed node to a healthy node. I iterate, we simply specify the target state (6 nodes) and not where to deploy, how to address the failure scenarios etc. Remember declarative and not imperative.
In the above scenario, we have 1 master and 2 nodes. We can ask K8S to deploy 6 pods (application instances) onto the nodes and K8S will automatically schedule the pods across the nodes. In case one of the node goes down, then K8S will automatically reschedule the pods from the failed node to a healthy node. I iterate, we simply specify the target state (6 nodes) and not where to deploy, how to address the failure scenarios etc. Remember declarative and not imperative.
For some reason it takes ~6 minutes for the pods to be rescheduled on the healthy nodes, even after the configuration changes mentioned here. Need to look into this a bit more.
Here is a video demoing the same in a small cluster. We can notice that when one of the node goes down, automatically K8S will reschedule the corresponding pods to a healthy node. We don't need to wake in the middle of the night to rectify a problem as long as have additional resources in case of failures.
Here are the sequence of steps. The same steps can be executed on a K8S cluster on the Cloud or locally on your Laptop. In this scenario, I am running the K8S Cluster on my Laptop. Also, the sequence of steps seem to be lengthy, but can be automated using Helm, which is a package manager for K8S.
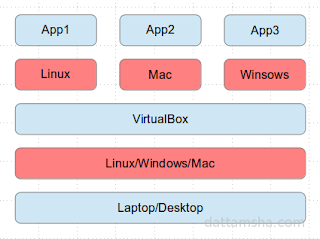
Step 1 : Start the K8S cluster in VirtualBox.
Step 2 : Make sure the cluster is up. Wait for a few minutes for the cluster to be up. Freezing the recording here.
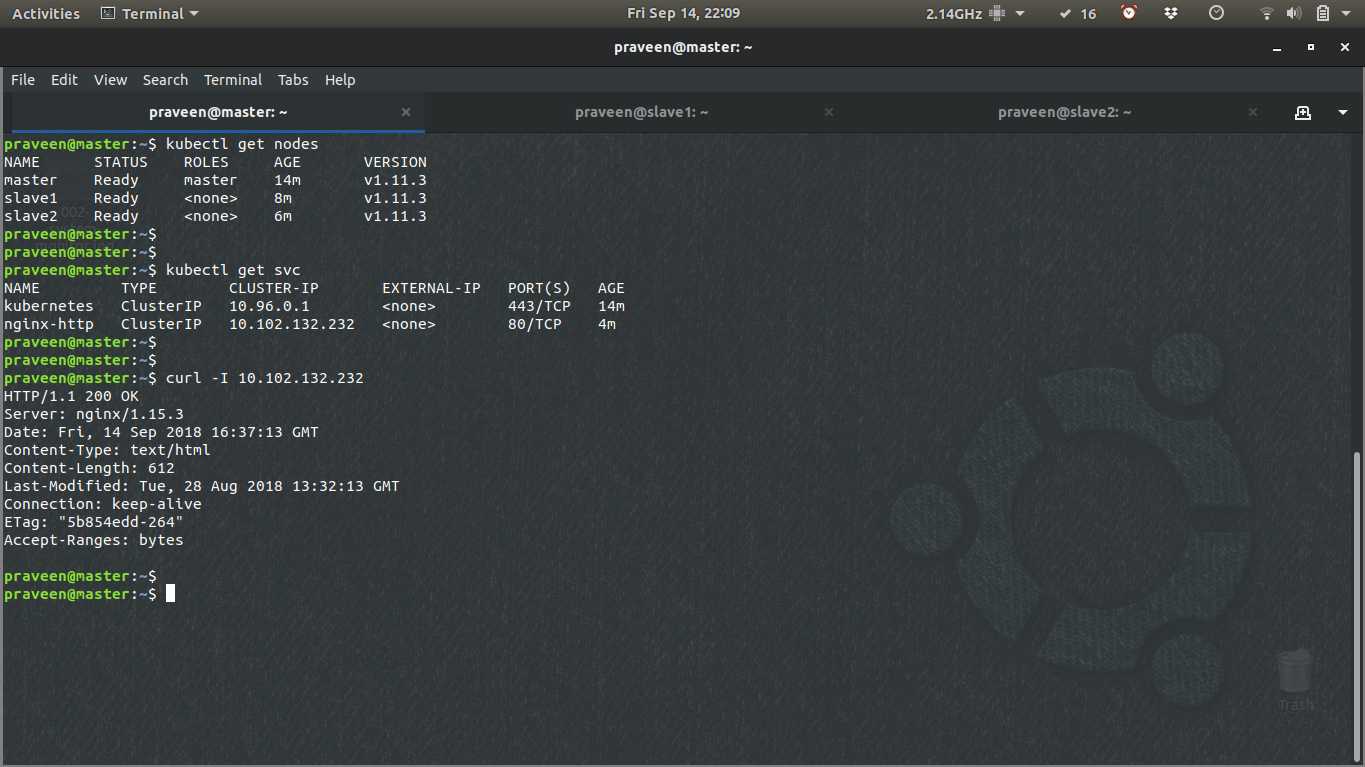
kubectl get nodes
Step 3 : Clean the cluster of all the resources
kubectl delete po,svc,rc,rs,deploy --all
Step 4 : Deploy the Docker ghost image (default replica is 1)
kubectl run ghost --image=ghost
Step 5 : Check the number of pods (should be 1)
kubectl get rs
Step 6 : Check the node in which they are deployed
kubectl get pods -o wide | grep -i running
Step 7 : Scale the application (replicas to 6)
kubectl scale deployment --replicas=6 ghost
Step 8 : Check the number of pods again (should be 6)
kubectl get rs
Step 9 : Check the node in which they are deployed (The K8S scheduler should load balance the pods across slave1 and slave2)
kubectl get pods -o wide | grep -i running
Step 10 : ssh to one slave of the bring down one of the node
sudo init 0
Step 11 : Wait for a few minutes (default ~6min). Freezing the recording here.
Step 12 : Check if the pods are deployed to healthy node
kubectl get pods -o wide | grep -i running
Hurray!!! The pods have been automatically deployed on a healthy node.
Additional steps (not required for this scenario)
Step 1 : Expose the pod as a service
kubectl expose deployment ghost --port=2368 --type=NodePort
Step 2 : Get the port of the service
kubectl get services ghost
Step 3 : Access the webpage using the above port
http://master:port
In the upcoming blogs, I will try to explain a few more features of K8S using demos. Keep looking !!!
For some reason it takes ~6 minutes for the pods to be rescheduled on the healthy nodes, even after the configuration changes mentioned here. Need to look into this a bit more.
Here is a video demoing the same in a small cluster. We can notice that when one of the node goes down, automatically K8S will reschedule the corresponding pods to a healthy node. We don't need to wake in the middle of the night to rectify a problem as long as have additional resources in case of failures.
Here are the sequence of steps. The same steps can be executed on a K8S cluster on the Cloud or locally on your Laptop. In this scenario, I am running the K8S Cluster on my Laptop. Also, the sequence of steps seem to be lengthy, but can be automated using Helm, which is a package manager for K8S.
Step 1 : Start the K8S cluster in VirtualBox.
Step 2 : Make sure the cluster is up. Wait for a few minutes for the cluster to be up. Freezing the recording here.
kubectl get nodes
Step 3 : Clean the cluster of all the resources
kubectl delete po,svc,rc,rs,deploy --all
Step 4 : Deploy the Docker ghost image (default replica is 1)
kubectl run ghost --image=ghost
Step 5 : Check the number of pods (should be 1)
kubectl get rs
Step 6 : Check the node in which they are deployed
kubectl get pods -o wide | grep -i running
Step 7 : Scale the application (replicas to 6)
kubectl scale deployment --replicas=6 ghost
Step 8 : Check the number of pods again (should be 6)
kubectl get rs
Step 9 : Check the node in which they are deployed (The K8S scheduler should load balance the pods across slave1 and slave2)
kubectl get pods -o wide | grep -i running
Step 10 : ssh to one slave of the bring down one of the node
sudo init 0
Step 11 : Wait for a few minutes (default ~6min). Freezing the recording here.
Step 12 : Check if the pods are deployed to healthy node
kubectl get pods -o wide | grep -i running
Hurray!!! The pods have been automatically deployed on a healthy node.
Additional steps (not required for this scenario)
Step 1 : Expose the pod as a service
kubectl expose deployment ghost --port=2368 --type=NodePort
Step 2 : Get the port of the service
kubectl get services ghost
Step 3 : Access the webpage using the above port
http://master:port
In the upcoming blogs, I will try to explain a few more features of K8S using demos. Keep looking !!!
















 Desktop")
