For those who wanted to get started with Hadoop as with any other technology there are a couple of steps involved from downloading/installing/configuring Linux and all the way to Hadoop and related frameworks. These steps can be avoided using a Cloud services like Amazon EMR.
HortonWorks recently announced a VM to get started easily with Hadoop and related frameworks. MapR, Cloudera and others also had similar VMs from some time. Using these VMs make simple to get started with Big Data, but there are some challenges using them. Like not all frameworks are installed in the Cloudera's CDH (not sure why???), there is no option for automatically installing Cassandra or Pig and have to be installed manually. Also, all the services are started during startup which makes the whole VM slow on some of the machines.
To overcome some of these limitations a Big Data VM has been created for those who are novice to Linux and the Big Data frameworks. Check this screencast on how easy it is use the Big Data VM (play in VLC player). The steps involved to get started with the VM are to download/install VirtualBox and then configure the Big Data VM in it. VirtualBox is available on Windows/Mac/Linux/Solaris, so the Bit Data VM can run on any of these Operating Systems. All that is needed is 12GB of free Hard Disk, 3-4 GB RAM and a Laptop/Desktop with a decent processor and we are ready to jump into the Big Data world.
Once the Big Data VM has been configured, it will appear as below
To overcome some of these limitations a Big Data VM has been created for those who are novice to Linux and the Big Data frameworks. Check this screencast on how easy it is use the Big Data VM (play in VLC player). The steps involved to get started with the VM are to download/install VirtualBox and then configure the Big Data VM in it. VirtualBox is available on Windows/Mac/Linux/Solaris, so the Bit Data VM can run on any of these Operating Systems. All that is needed is 12GB of free Hard Disk, 3-4 GB RAM and a Laptop/Desktop with a decent processor and we are ready to jump into the Big Data world.
Once the Big Data VM has been configured, it will appear as below

The Big Data VM has to be selected in the left pane and then started. We have a Linux running on top of Windows or in fact any other operating system. In the below screen, Big Data VM runs on top of Windows 7 (host OS). The VM has been built using Ubuntu 12.04 (guest OS), because it's more user friendly when compared to other Operating Systems in the Linux family (performance is not a concern here).

The environment is all setup to start playing with Hadoop and related Big Data frameworks. Cassandra, HBase, Hive, Pig, Sqoop, ZooKeeper and Hadoop have been installed and configured in the VM. MySQL also has been installed for use with Sqoop.
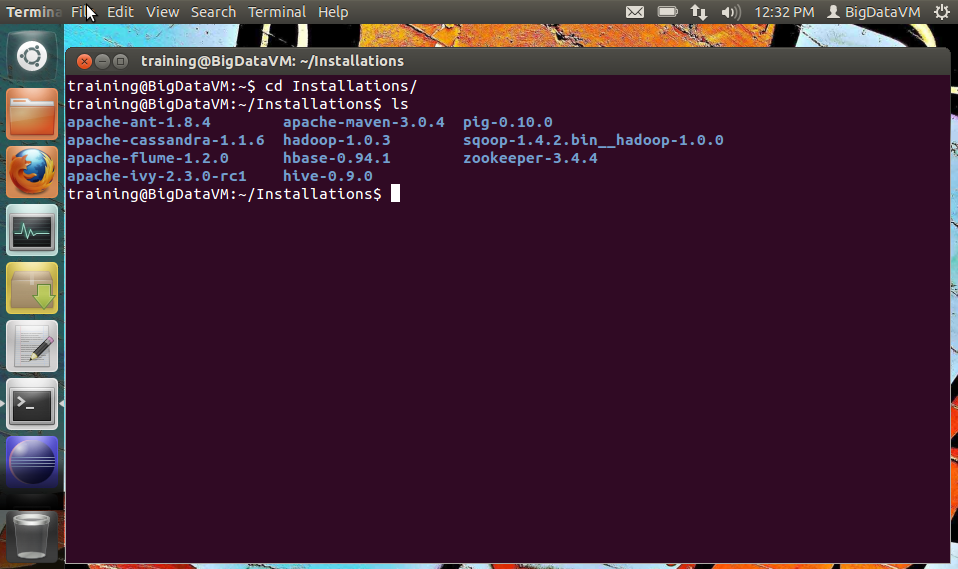
Also included are some public data sets and code to process the data sets in the VM. The commands to start the different daemons (Hadoop, HBase etc) and to run the different jobs/start shells are there in the VMCommands folder.

Just use the terminal quick launcher on the left to start a terminal and go to the Hadoop installation folder (cd $HADOOP_HOME) and then start the Hadoop daemons (bin/start-all.sh). We are all set to put files in HDFS and run MapReduce jobs on them.

Finally, Eclipse has been installed for developing/debugging/executing MapReduce programs and for others tasks like developing Pig/Hive UDF. Below screen shows a Pig UDF being developed. Once the developing/debugging/executing has been completed in Eclipse, then a jar file can be created and easily run in the VM or run in a entirely different Hadoop cluster.

Here is a crude document with some screen shots on how east it is to get started with installing VirtualBox and configuring the Big Data VM in it. Once the VirtualBox and the Big Data VM has been downloaded, it's a matter of minutes to get started with the Big Data world.
The Big Data VM had been provided during the various Hadoop related trainings and it was very useful for the trainees to get started easily and quickly. For more information about the Big Data VM and related Hadoop training, please contact at praveensripati@gmail.com or also check here for more details.
Happy Hadooping !!!!