Note : Also don't forget to do check another entry on how to get some interesting facts from Twitter using R here. And also this entry on how to use Oozie for automating the below workflow. Here is a new blog on how to do the same analytics with Pig (using elephant-bird).
It's not a hard rule, but almost 80% of the data is unstructured, while the remaining 20% is structured data. RDBMS helps to store/process the structured data (20%), while Hadoop solves the problem of storing/processing both types of data. The good thing about Hadoop, is that it scales incrementally with less CAPEX in terms of software and hardware.
With the ever increasing usage of smart devices and the high speeds internet, unstructured data had been growing at a very fast rate. It's common to Tweet from a smart phone, take a picture and share it in Facebook.
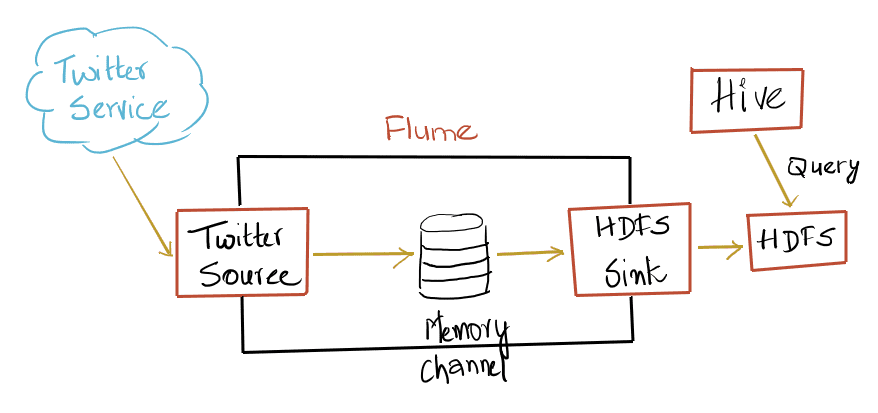
In this blog we will try to get Tweets using Flume and save them into HDFS for later analysis. Twitter exposes the API (more here) to get the Tweets. The service is free, but requires the user to register for the service. Cloudera wrote a three part series (1, 2, 3) for Twitter Analysis using Hadoop, the code for the same is here. For the impatient, I will quickly summarize how to get data into HDFS using Flume and start doing some analytics using Hive.
Flume has the concepts of agents. The sources, sinks and the intermediate channels are the different types of agents. The sources can push/pull the data and send it to the different channels which in turn will send the data to the different sinks. Flume decouples the source (Twitter) and the sink (HDFS) in this case. Both the source and the sink can operate at different speeds, also it's much easier to add new sources and sinks. Flume comes with a set of sources, channels, sinks and new onces can be implemented by extending the Flume base classes.

1) The first step is to create an application in https://dev.twitter.com/apps/ and then generate the corresponding keys.

2) Assuming that Hadoop has already been installed and configured, the next step is download Flume and extract it to any folder.
3) Download the flume-sources-1.0-SNAPSHOT.jar and add it to the flume class path as shown below in the conf/flume-env.sh file
4) The conf/flume.conf should have all the agents (flume, memory and hdfs) defined as below
The TwitterAgent.sources.Twitter.keywords value can be modified to get the tweets for some other topic like football, movies etc.
5) Start flume using the below command

6) Next download and extract Hive. Modify the conf/hive-site.xml to include the locations of the NameNode and the JobTracker as below
8) Start the Hive shell using the hive command and register the hive-serdes-1.0-SNAPSHOT.jar file downloaded earlier.
One of the way to determine who is the most influential person in a particular field is to to figure out whose tweets are re-tweeted the most. Give enough time for Flume to collect Tweets from Twitter to HDFS and then run the below query in Hive to determine the most influential person.
Happy Hadooping !!!
Edit (21st March, 2013) : Hortonworks blogged a two part series (1 and 2) on Twitter data processing using Hive.
Edit (30th March, 2016) : With the latest version of Flume, the following error is thrown because of the conflicts in the libraries
java.lang.NoSuchMethodError: twitter4j.FilterQuery.setIncludeEntities(Z)Ltwitter4j/FilterQuery;
at com.cloudera.flume.source.TwitterSource.start(TwitterSource.java:139)'
One solution is to remove the below libraries in the Flume lib folder. There are a couple of more solutions in this StackOverflow article.
It's not a hard rule, but almost 80% of the data is unstructured, while the remaining 20% is structured data. RDBMS helps to store/process the structured data (20%), while Hadoop solves the problem of storing/processing both types of data. The good thing about Hadoop, is that it scales incrementally with less CAPEX in terms of software and hardware.
With the ever increasing usage of smart devices and the high speeds internet, unstructured data had been growing at a very fast rate. It's common to Tweet from a smart phone, take a picture and share it in Facebook.
In this blog we will try to get Tweets using Flume and save them into HDFS for later analysis. Twitter exposes the API (more here) to get the Tweets. The service is free, but requires the user to register for the service. Cloudera wrote a three part series (1, 2, 3) for Twitter Analysis using Hadoop, the code for the same is here. For the impatient, I will quickly summarize how to get data into HDFS using Flume and start doing some analytics using Hive.
Flume has the concepts of agents. The sources, sinks and the intermediate channels are the different types of agents. The sources can push/pull the data and send it to the different channels which in turn will send the data to the different sinks. Flume decouples the source (Twitter) and the sink (HDFS) in this case. Both the source and the sink can operate at different speeds, also it's much easier to add new sources and sinks. Flume comes with a set of sources, channels, sinks and new onces can be implemented by extending the Flume base classes.
1) The first step is to create an application in https://dev.twitter.com/apps/ and then generate the corresponding keys.

2) Assuming that Hadoop has already been installed and configured, the next step is download Flume and extract it to any folder.
3) Download the flume-sources-1.0-SNAPSHOT.jar and add it to the flume class path as shown below in the conf/flume-env.sh file
FLUME_CLASSPATH="/home/training/Installations/apache-flume-1.3.1-bin/flume-sources-1.0-SNAPSHOT.jar"The jar contains the java classes to pull the Tweets and save them into HDFS.
4) The conf/flume.conf should have all the agents (flume, memory and hdfs) defined as below
TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS TwitterAgent.sources.Twitter.type = com.cloudera.flume.source.TwitterSource TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sources.Twitter.consumerKey = <consumerKey> TwitterAgent.sources.Twitter.consumerSecret = <consumerSecret> TwitterAgent.sources.Twitter.accessToken = <accessToken> TwitterAgent.sources.Twitter.accessTokenSecret = <accessTokenSecret> TwitterAgent.sources.Twitter.keywords = hadoop, big data, analytics, bigdata, cloudera, data science, data scientiest, business intelligence, mapreduce, data warehouse, data warehousing, mahout, hbase, nosql, newsql, businessintelligence, cloudcomputing TwitterAgent.sinks.HDFS.channel = MemChannel TwitterAgent.sinks.HDFS.type = hdfs TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/flume/tweets/ TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000 TwitterAgent.sinks.HDFS.hdfs.rollSize = 0 TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000 TwitterAgent.channels.MemChannel.type = memory TwitterAgent.channels.MemChannel.capacity = 10000 TwitterAgent.channels.MemChannel.transactionCapacity = 100The consumerKey, consumerSecret, accessToken and accessTokenSecret have to be replaced with those obtained from https://dev.twitter.com/apps. And, TwitterAgent.sinks.HDFS.hdfs.path should point to the NameNode and the location in HDFS where the tweets will go to.
The TwitterAgent.sources.Twitter.keywords value can be modified to get the tweets for some other topic like football, movies etc.
5) Start flume using the below command
bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n TwitterAgentAfter a couple of minutes the Tweets should appear in HDFS.

6) Next download and extract Hive. Modify the conf/hive-site.xml to include the locations of the NameNode and the JobTracker as below
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>7) Download hive-serdes-1.0-SNAPSHOT.jar to the lib directory in Hive. Twitter returns Tweets in the JSON format and this library will help Hive understand the JSON format.
8) Start the Hive shell using the hive command and register the hive-serdes-1.0-SNAPSHOT.jar file downloaded earlier.
ADD JAR /home/training/Installations/hive-0.9.0/lib/hive-serdes-1.0-SNAPSHOT.jar;9) Now, create the tweets table in Hive
CREATE EXTERNAL TABLE tweets (
id BIGINT,
created_at STRING,
source STRING,
favorited BOOLEAN,
retweet_count INT,
retweeted_status STRUCT<
text:STRING,
user:STRUCT<screen_name:STRING,name:STRING>>,
entities STRUCT<
urls:ARRAY<STRUCT<expanded_url:STRING>>,
user_mentions:ARRAY<STRUCT<screen_name:STRING,name:STRING>>,
hashtags:ARRAY<STRUCT<text:STRING>>>,
text STRING,
user STRUCT<
screen_name:STRING,
name:STRING,
friends_count:INT,
followers_count:INT,
statuses_count:INT,
verified:BOOLEAN,
utc_offset:INT,
time_zone:STRING>,
in_reply_to_screen_name STRING
)
ROW FORMAT SERDE 'com.cloudera.hive.serde.JSONSerDe'
LOCATION '/user/flume/tweets';
Now that we have the data in HDFS and the table created in Hive, lets run some queries in Hive.One of the way to determine who is the most influential person in a particular field is to to figure out whose tweets are re-tweeted the most. Give enough time for Flume to collect Tweets from Twitter to HDFS and then run the below query in Hive to determine the most influential person.
SELECT t.retweeted_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name as retweeted_screen_name, retweeted_status.text, max(retweet_count) as retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweeted_screen_name ORDER BY total_retweets DESC LIMIT 10;Similarly to know which user has the most number of followers, the below query helps.
select user.screen_name, user.followers_count c from tweets order by c desc;For sake of making it simple, partitions have not been created in Hive. Partitions can be created in Hive using Oozie at regular intervals to make the queries run faster if queried for a particular period time. Creating partitions will be covered in another blog.
Happy Hadooping !!!
Edit (21st March, 2013) : Hortonworks blogged a two part series (1 and 2) on Twitter data processing using Hive.
Edit (30th March, 2016) : With the latest version of Flume, the following error is thrown because of the conflicts in the libraries
java.lang.NoSuchMethodError: twitter4j.FilterQuery.setIncludeEntities(Z)Ltwitter4j/FilterQuery;
at com.cloudera.flume.source.TwitterSource.start(TwitterSource.java:139)'
One solution is to remove the below libraries in the Flume lib folder. There are a couple of more solutions in this StackOverflow article.
lib/twitter4j-core-3.0.3.jar
lib/twitter4j-media-support-3.0.3.jar
lib/twitter4j-stream-3.0.3.jar
Awesome Post Praveen!! Just to clarify flume-env.sh should be in conf folder or bin folder ? when i followed apache flume instillation steps i created flume-env.sh in conf folder.
ReplyDeleteThe flume-env.sh should be in the conf folder and not the bin folder. I have updated the blog.
Deletehi praveen
DeleteTweets in which format? I have loaded tweets data into hive table. Now i gave command in hive datadbase like that select * from table name, its not giving sql structure. Please help me on this praveen
when executing flume command i am getting below exception
Delete2016-09-28 17:38:25,545 (Twitter Stream consumer-1[Establishing connection]) [INFO - twitter4j.internal.logging.SLF4JLogger.info(SLF4JLogger.java:83)] Waiting for 10000 milliseconds
2016-09-28 17:38:35,547 (Twitter Stream consumer-1[Waiting for 10000 milliseconds]) [ERROR - org.apache.flume.source.twitter.TwitterSource.onException(TwitterSource.java:331)] Exception while streaming tweets
404:The URI requested is invalid or the resource requested, such as a user, does not exist.
Unknown URL. See Twitter Streaming API documentation at http://dev.twitter.com/pages/streaming_api
if u know pls let me know
Please post the solution for this. Even I am facing this issue.
DeleteThanks
Thanks for posting awesome tutorial. I have configured hadoop cluster and now I am trying to follow your tutorial for twitter data analysis. I have installed flume and completed until step 3. For the step 4 when you mention conf/flume.conf are you referring to flume-conf.properties.template file inside conf folder? If not, where can I find that file and define agent fields. Please let me know. I would really appreciate your help. Thanks in advance!!
ReplyDeleteReema please copy fume-conf.properties.template to flme.conf and replace the configurations above mentioned (in step 4)
DeleteThanks much!!
DeleteI am not getting the tweets from twitter... the process is stopping at this point mentioned below.... !! Nothing beyond this step.
ReplyDelete13/04/18 04:13:11 INFO instrumentation.MonitoredCounterGroup: Monitoried counter group for type: SINK, name: HDFS, registered successfully.
13/04/18 04:13:11 INFO instrumentation.MonitoredCounterGroup: Component type: SINK, name: HDFS started
****************************************************************
I have been trying to change some files due the error i have been observing.
In flume.conf have changed the TwitterAgent.sources = TwitterSource
whereas the original content is TwitterAgent.sources = Twitter.
This comment has been removed by the author.
ReplyDeletei need our help .. could u pls help me out ...
DeleteActually im using apache-flume-1.3.1 to extract the log file into my hdfs ... actually everthing has to be clear .. my flume can try to put the file in hdfs but the issue is it cant able to pull all the content .. clearly says i have a 9.7mb of log file(temporarly store in local) i can give the path to store in hdfs sink .... flume can store it only 3.5 kb of original file sometimes if i refresh the original log file it ll store in hdfs nearly 2 mb but in suffule process and some of the line has not be store that can be neglected similary it cant start it from 1st the line and it take as in centre of line some time .. what can i do for that how can i configure in my flume configuration . solve this from problem .. help me out
thanks you
regards
Thanks for the great post, however after running step 5) l get the following "ERROR properties.PropertiesFileConfigurationProvider: Failed to load configuration data. Exception follows org.apache.flume.FlumeException: Unable to load source type: com.cloudera.flume.source.TwitterSource".
ReplyDeletePlease assist.
Looks like you need to make sure your FLUME_CLASSPATH is pointing to the .jar file.
DeleteIn step 5, I had no tweets coming into HDFS.
ReplyDeleteBut I found time out information in the console.
Anyone can help?
2013-05-10 14:25:53,941 (Twitter Stream consumer-1[Establishing connection]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:75)] Post Params: count=0&track=hadoop%2Cbig%20data%2Canalytics%2Cbigdata%2Ccloudera%2Cdata%20science%2Cdata%20scientist%2Cbusiness%20intelligence%2Cmapreduce%2Cdata%20warehouse%2Cdata%20warehousing%2Cmahout%2Chbase%2Cnosql%2Cnewsql%2Cbusinessintelligence%2Ccloudcomputing&include_entities=true
2013-05-10 14:26:07,436 (conf-file-poller-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:126)] Checking file:conf/flume.conf for changes
2013-05-10 14:26:14,039 (Twitter Stream consumer-1[Establishing connection]) [INFO - twitter4j.internal.logging.SLF4JLogger.info(SLF4JLogger.java:83)] connect timed out
2013-05-10 14:26:14,039 (Twitter Stream consumer-1[Establishing connection]) [INFO - twitter4j.internal.logging.SLF4JLogger.info(SLF4JLogger.java:83)] Waiting for 16000 milliseconds
Hi Praveen,
ReplyDeleteI got tweets coming into HadoopFS but when we are writing various queries i am getting this error: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.MapRedTask
LMK what needs to be done here to run your queries?
Thanks,
NT
This comment has been removed by the author.
DeleteI also got the same error..
Deletejust add hive-serdes-1.0-SNAPSHOT.jar to you hive shell ..
Does anyone know why I might be getting the following error?
ReplyDelete[ERROR - org.apache.flume.lifecycle.LifecycleSupervisor$MonitorRunnable.run(LifecycleSupervisor.java:253)] Unable to start EventDrivenSourceRunner: { source:com.cloudera.flume.source.TwitterSource{name:Twitter,state:IDLE} } - Exception follows.
java.lang.NoSuchMethodError: twitter4j.FilterQuery.setIncludeEntities(Z)Ltwitter4j/FilterQuery;
This comment has been removed by the author.
DeleteI got the same error. This is how I resolved it
Deletea) First checked the jar file to make sure that FilterQuery.class exists in flume-sources-1.0-SNAPSHOT.jar
[root@localhost lib]# /usr/java/jdk1.6.0_31/bin/jar tvf /tmp/flume-sources-1.0-SNAPSHOT.jar
You may see an item
4451 Tue Nov 13 10:06:42 PST 2012 twitter4j/FilterQuery.class
So it is there.
Now need to verify that the class has the method setIncludeEntities
Extracted the jar file and viewed the source code, I used show my code online class decompiler. See
http://www.showmycode.com/
Found that the method setIncludeEntities exists. So FLUME_CLASSPATH ( flume-sources-1.0-SNAPSHOT.jar) is correct.
Now, it seems the issues is another jar file which has the same class, but does not have this method is getting picked by the flume agent java process and causing the issue.
So we need to find that jar, for that we need the full class path when starting the flume agent
I run the below command as posted in the blog
[root@localhost lib]# /usr/bin/flume-ng agent start --conf /etc/flume-ng/conf/ -f /etc/flume-ng/conf/flume.conf -Dflume.root.logger=DEBUG,console -n TwitterAgent
Which shows a very lengthy classpath
[root@localhost lib]# /usr/bin/flume-ng agent start --conf /etc/flume-ng/conf/ -f /etc/flume-ng/conf/flume.conf -Dflume.root.logger=DEBUG,console -n TwitterAgent
Info: Sourcing environment configuration script /etc/flume-ng/conf/flume-env.sh
Info: Including Hadoop libraries found via (/usr/bin/hadoop) for HDFS access
Info: Excluding /usr/lib/hadoop/lib/slf4j-api-1.6.1.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-log4j12-1.6.1.jar from classpath
Info: Excluding /usr/lib/hadoop-0.20-mapreduce/lib/slf4j-api-1.6.1.jar from classpath
Info: Including HBASE libraries found via (/usr/bin/hbase) for HBASE access
Info: Excluding /usr/lib/hbase/bin/../lib/slf4j-api-1.6.1.jar from classpath
Info: Excluding /usr/lib/zookeeper/lib/slf4j-api-1.6.1.jar from classpath
Info: Excluding /usr/lib/zookeeper/lib/slf4j-log4j12-1.6.1.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-api-1.6.1.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-log4j12-1.6.1.jar from classpath
Info: Excluding /usr/lib/hadoop-0.20-mapreduce/lib/slf4j-api-1.6.1.jar from classpath
+ exec /usr/java/jdk1.6.0_31/bin/java -Xmx20m -Dflume.root.logger=DEBUG,console -cp '/etc/flume-ng/conf:/usr/lib/flume-ng/lib/*:/tmp/flume-sources-1.0-SNAPSHOT.jar:/etc/hadoop/conf:/usr/lib/hadoop/lib/activation-1.1.jar:/usr/lib/hadoop/lib/asm-3.2.jar:..........................................................
Note the beginning of the classpath
-cp '/etc/flume-ng/conf:/usr/lib/flume-ng/lib/*:/tmp/flume-sources-1.0-SNAPSHOT.jar:
See the jar files in /usr/lib/flume-ng/lib/*
Check the content of the jar files for FilterQuery.class
[root@localhost lib]# find . -name "*.jar" | xargs grep FilterQuery.class
Binary file ./search-contrib-0.9.1-cdh4.3.0-SNAPSHOT-jar-with-dependencies.jar matches
[root@localhost lib]#
So we have another JAR file search-contrib-0.9.1-cdh4.3.0-SNAPSHOT-jar-with-dependencies.jar with the same class and conflicting with correct one in FLUME_CLASSPATH
Temporarily rename it to .org extension, so that it will be excluded from classpath at the startup
[root@localhost lib]# mv search-contrib-0.9.1-cdh4.3.0-SNAPSHOT-jar-with-dependencies.jar search-contrib-0.9.1-cdh4.3.0-SNAPSHOT-jar-with-dependencies.jar.org
[root@localhost lib]#
Now start the flume agent again
[root@localhost lib]# /usr/bin/flume-ng agent start --conf /etc/flume-ng/conf/ -f /etc/flume-ng/conf/flume.conf -Dflume.root.logger=DEBUG,console -n TwitterAgent
It worked like a charm. I do not know the effect of temporarily renaming and excluding the search-contrib-0.9.1-cdh4.3.0-SNAPSHOT-jar-with-dependencies.jar from the classpath, on other components..but it worked for this scenario..I will continue my investigation further...
If anybody has a better solution, please post it
Hi Praveen and thanks for this tutorial,
DeleteI have the same problem and followed your procedure. The other JAR file conflicting with flume-sources-1.0-SNAPSHOT.jar is twitter4j-stream-3.0.3.jar. Obviously, that last file cannot be renamed without error :
2013-10-04 10:41:29,873 (Twitter Stream consumer-1[Establishing connection]) [INFO - twitter4j.internal.logging.SLF4JLogger.info(SLF4JLogger.java:83)] 401:Authentication credentials (https://dev.twitter.com/pages/auth) were missing or incorrect. Ensure that you have set valid consumer key/secret, access token/secret, and the system clock is in sync.
Can you help me?
Hi praveen,
ReplyDeletei have done all the steps in the blog and i got the same results.now how can we create partitions in hive using oozie at regular intervals?
and i want to schedule them in oozie. Is it possible?
i am not able eto create hive table nd i am using apache hadoop not cloudera can you please help me
DeleteHi,
ReplyDeleteI am getting below error
HDFS IO error
java.io.IOException: Callable timed out after 10000 ms on file: hdfs://localhost:8502/user/flume/tweets//FlumeData.1375149990564.tmp
at org.apache.flume.sink.hdfs.BucketWriter.callWithTimeout(BucketWriter.java:550)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:220)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:383)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:392)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:68)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:147)
at java.lang.Thread.run(Thread.java:679)
Caused by: java.util.concurrent.TimeoutException
at java.util.concurrent.FutureTask$Sync.innerGet(FutureTask.java:258)
at java.util.concurrent.FutureTask.get(FutureTask.java:119)
at org.apache.flume.sink.hdfs.BucketWriter.callWithTimeout(BucketWriter.java:543)
... 6 more
could you please help me out ?
This comment has been removed by the author.
ReplyDeleteHi Praveen/Guys,
ReplyDeleteI ran the same code on my HortonWorks cluster and once the sink and channel have started, the program times out trying to connect to twitter.
Is this because this code is cloudera specific as I see here in conf file.
TwitterAgent.sources.Twitter.type = com.cloudera.flume.source.TwitterSource
Would be glad if someone could help.
Here is the timout portion of the log:
25 Sep 2013 07:47:54,763 INFO [conf-file-poller-0] (org.apache.flume.node.nodemanager.DefaultLogicalNodeManager.startAllComponents:141) - Starting Sink HDFS
25 Sep 2013 07:47:54,763 INFO [conf-file-poller-0] (org.apache.flume.node.nodemanager.DefaultLogicalNodeManager.startAllComponents:152) - Starting Source Twitter
25 Sep 2013 07:47:54,766 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.register:89) - Monitoried counter group for type: SINK, name: HDFS, registered successfully.
25 Sep 2013 07:47:54,766 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.start:73) - Component type: SINK, name: HDFS started
25 Sep 2013 07:47:54,770 INFO [Twitter Stream consumer-1[initializing]] (twitter4j.internal.logging.SLF4JLogger.info:83) - Establishing connection.
25 Sep 2013 07:48:15,182 INFO [Twitter Stream consumer-1[Establishing connection]] (twitter4j.internal.logging.SLF4JLogger.info:83) - connect timed out
.
.
.
.
.
i got the same error.....are you able to resolve it
Deletegood post....
ReplyDelete-Dflume.root.logger=DEBUG,console without this line i got error any idea why? otherwise fine.
ReplyDeleteHi Praveen/Guys,
ReplyDeleteI am getting an error while getting Tweets into HDFS. Below is the logs for the same.
13/11/21 06:00:01 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: Waiting for 250 milliseconds
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: Waiting for 500 milliseconds
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
13/11/21 06:00:02 INFO twitter4j.TwitterStreamImpl: Waiting for 1000 milliseconds
13/11/21 06:00:03 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/21 06:00:03 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
13/11/21 06:00:03 INFO twitter4j.TwitterStreamImpl: Waiting for 2000 milliseconds
13/11/21 06:00:05 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/21 06:00:05 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
13/11/21 06:00:05 INFO twitter4j.TwitterStreamImpl: Waiting for 4000 milliseconds
13/11/21 06:00:09 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/21 06:00:09 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
13/11/21 06:00:09 INFO twitter4j.TwitterStreamImpl: Waiting for 8000 milliseconds
13/11/21 06:00:17 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/21 06:00:17 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
13/11/21 06:00:17 INFO twitter4j.TwitterStreamImpl: Waiting for 16000 milliseconds
13/11/21 06:00:33 INFO twitter4j.TwitterStreamImpl: Establishing connection.
Can i get some help ?
check your network connection
DeleteI've been getting the some error when i'm trying to run this
ReplyDelete/usr/bin/flume-ng agent -n kings-river-flume -c conf -f /usr/lib/flume-ng/conf/flume.conf ( i used the default " kings-river-flume" twitter agent name (becouse i couldn't modify /etc/default/flume-ng-agent file) just hoping this was the problem ) but i'm getting this error
13/11/18 16:44:38 INFO lifecycle.LifecycleSupervisor: Starting lifecycle supervisor 1
13/11/18 16:44:38 INFO node.FlumeNode: Flume node starting - kings-river-flume
13/11/18 16:44:38 INFO nodemanager.DefaultLogicalNodeManager: Node manager starting
13/11/18 16:44:38 INFO lifecycle.LifecycleSupervisor: Starting lifecycle supervisor 9
13/11/18 16:44:38 INFO properties.PropertiesFileConfigurationProvider: Configuration provider starting
13/11/18 16:44:39 INFO properties.PropertiesFileConfigurationProvider: Reloading configuration file:/usr/lib/flume-ng/conf/flume.conf
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Added sinks: HDFS Agent: TwitterAgent
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Processing:HDFS
13/11/18 16:44:39 INFO conf.FlumeConfiguration: Post-validation flume configuration contains configuration for agents: [TwitterAgent]
13/11/18 16:44:39 WARN properties.PropertiesFileConfigurationProvider: No configuration found for this host:kings-river-flume
13/11/18 16:45:05 INFO node.FlumeNode: Flume node stopping - kings-river-flume
13/11/18 16:45:05 INFO lifecycle.LifecycleSupervisor: Stopping lifecycle supervisor 8
13/11/18 16:45:05 INFO properties.PropertiesFileConfigurationProvider: Configuration provider stopping
13/11/18 16:45:05 INFO nodemanager.DefaultLogicalNodeManager: Node manager stopping
13/11/18 16:45:05 INFO lifecycle.LifecycleSupervisor: Stopping lifecycle supervisor 8
Can anybody help?
Hello All,
ReplyDeleteI am receiving following error:
13/11/27 00:11:15 INFO twitter4j.TwitterStreamImpl: Establishing connection.
13/11/27 00:11:17 INFO twitter4j.TwitterStreamImpl: 406:Returned by the Search API when an invalid format is specified in the request.
Returned by the Streaming API when one or more of the parameters are not suitable for the resource. The track parameter, for example, would throw this error if:
The track keyword is too long or too short.
The bounding box specified is invalid.
No predicates defined for filtered resource, for example, neither track nor follow parameter defined.
Follow userid cannot be read.
Parameter track item index 0 too short:
13/11/27 00:11:17 WARN twitter4j.TwitterStreamImpl: Parameter not accepted with the role. 406:Returned by the Search API when an invalid format is specified in the request.
Returned by the Streaming API when one or more of the parameters are not suitable for the resource. The track parameter, for example, would throw this error if:
The track keyword is too long or too short.
The bounding box specified is invalid.
No predicates defined for filtered resource, for example, neither track nor follow parameter defined.
Follow userid cannot be read.
Parameter track item index 0 too short:
Can someone help or guide me?
I defined the keywords exactly as in the example above...
Many thanks,
Filip
Thanks Praveen, debugging tips helped me
ReplyDeleteThanks Suresh, nice work around. Solved the problem for me.
ReplyDeleteI am facing this error althogh keys are correct
ReplyDelete- 401:Authentication credentials (https://dev.twitter.com/docs/auth) were missing or incorrect. Ensure that you have set valid consumer key/secret, access token/secret, and the system clock is in sync.
For your kind help
Make sure you have tested your credentials(access token/secret) in Twitter site.
Deletehi attia elsayed iam also facing that problem did you find any solution????
Deleteplz reply
Thanks Suresh
ReplyDeleteA very nice blog ...configured Apache flume in seconds to get data from twitter...
hello,
ReplyDeletei am getting following error ,can someone help please
ERROR node.PollingPropertiesFileConfigurationProvider: Failed to load configuration data. Exception follows.
org.apache.flume.FlumeException: Unable to load source type: com.cloudera.flume.source.TwitterSource, class: com.cloudera.flume.source.TwitterSource
at org.apache.flume.source.DefaultSourceFactory.getClass(DefaultSourceFactory.java:67)
at org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:40)
at org.apache.flume.node.AbstractConfigurationProvider.loadSources(AbstractConfigurationProvider.java:327)
at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:102)
at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:140)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
Caused by: java.lang.ClassNotFoundException: com.cloudera.flume.source.TwitterSource
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:190)
at org.apache.flume.source.DefaultSourceFactory.getClass(DefaultSourceFactory.java:65)
Have you got any solution to this above error
DeleteHi Guys!!
ReplyDeleteI m pretty new to this field. I just wanted to know whether I could install flume,hive,oozie,etc without setting up the cloudera environment as suggested in the post. I have already a working pseudo distributed Hadoop cluster set up on my computer.
I am able to see tweets on console but not getting data into hdfs.
ReplyDeleteMy conf file is :
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
TwitterAgent.sources.Twitter.type = com.cloudera.flume.source.TwitterSource
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sources.Twitter.consumerKey = g2VoxfPOrIFKo0o58mhA
TwitterAgent.sources.Twitter.consumerSecret = L8H80HLL3q2LKTQQBX8BtyleMW1YdqxheWJxWozbcbg
TwitterAgent.sources.Twitter.accessToken = 1382526218-EvFiViJfN8b2CmPankGyaU6BHty1FXYDK1PLZEQ
TwitterAgent.sources.Twitter.accessTokenSecret = T0owrTGPvvw548CSiydTibwwi6ZfJJqLBW64vSot1jMTI
TwitterAgent.sources.Twitter.keywords = ind,pak,cricinfo,cricket,asiacup,rgsharma,viratkohli,rahane,dhoni,ipl,6thmatch,dhawan,shahidafridi,boomboom,
TwitterAgent.sinks.HDFS.channel = MemChannel
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://myhost:8020/whyt/twitter/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
Any idea;
hi jp, i'm facing the same problem. Did you find any solution?????
Deletepls reply
if your exception id HDFSIOERROR AS java.io.EOFException
Deletereplace hdfs://myhost:8020 with hdfs://localhost:8020 (if name node port number is 8020)
you can find configurations in /etc/alternatives/hadoop-0.20/core-site.xml
I could be wrong but I think the query to determine the most influential person has the following correction - replace 'max(retweet_count)' in the sub-query with 'max(retweeted_status.retweet_count)'.
ReplyDeleteHi every body , i have this error while i'm executing Flume , any help ??
ReplyDeleteorg.apache.flume.node.Application -f conf/flume.conf -n TwitterAgent
Erreur : impossible de trouver ou charger la classe principale org.apache.flume.node.Application
Hi, I need help. If someone could make the tutorial successfully fovar please contact lhssa@hotmail.com
ReplyDeletehow to view the output after processing mapreduce?? i
ReplyDeleteafter I installed hive,,i m getting output like this
ReplyDelete> select user.screen_name, user.followers_count c from tweets order by c desc;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapred.reduce.tasks=
Starting Job = job_201404170949_0035, Tracking URL = http://localhost:50030/jobdetails.jsp?jobid=job_201404170949_0035
Kill Command = /usr/lib/hadoop/bin/hadoop job -Dmapred.job.tracker=localhost:8021 -kill job_201404170949_0035
2014-05-14 00:49:49,071 Stage-1 map = 0%, reduce = 0%
2014-05-14 00:49:52,091 Stage-1 map = 0%, reduce = 100%
2014-05-14 00:49:53,108 Stage-1 map = 100%, reduce = 100%
Ended Job = job_201404170949_0035
OK
Time taken: 7.453 seconds
it doesnt show the table,,,bt i got the tweeted info as in tmp file,,,how to resolve this problem
um, this doesnt make any sense.........
ReplyDeleteWHERE is the conf/flume-ng??? Why should I have this? I only downloaded the flume-JAR but you didn't say anything about downloading more than this regarding flume?? is there something missing? what else should I DOWNLOAD?
Hi,
ReplyDeletePraveen Sripati
This post is very helpful for me every things work for me. i want to ask 1 question if i have to store date wise twitter data like (in 4/04/2014 Modi twits) then how to set flume agent or flume.conf.
I couldn't find setIncludeEntities method in my FilterQuery.class. Could you please tell me what to do to solve this issue.
ReplyDeleteThanks for great post !!!
ReplyDeleteAs mentioned in point 8, please give command to register "hive-serdes-1.0-SNAPSHOT.jar" in Hive shell.
Thanks for the Post!
ReplyDeleteI am getting following in console.
14/08/04 02:00:46 INFO instrumentation.MonitoredCounterGroup: Component type: SINK, name: HDFS started
14/08/04 02:00:46 INFO twitter4j.TwitterStreamImpl: Establishing connection.
14/08/04 02:01:08 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
14/08/04 02:01:08 INFO twitter4j.TwitterStreamImpl: Waiting for 250 milliseconds
14/08/04 02:01:08 INFO twitter4j.TwitterStreamImpl: Establishing connection.
14/08/04 02:01:08 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
14/08/04 02:01:08 INFO twitter4j.TwitterStreamImpl: Waiting for 500 milliseconds
14/08/04 02:01:09 INFO twitter4j.TwitterStreamImpl: Establishing connection.
14/08/04 02:01:09 INFO twitter4j.TwitterStreamImpl: stream.twitter.com
14/08/04 02:01:09 INFO twitter4j.TwitterStreamImpl: Waiting for 1000 milliseconds
...
and I couldn''t able to find tweets in HDFS.
Any help!
hey
Deletei am getting the same problem.My net is working fine but i am using cntlm.Have you found any solution for this?
I'm trying to start flume but keeping a permission denied error:
ReplyDelete-bash: /user/Flume/apache-flume-1.5.0-bin/bin/flume-ng: Permission denied
and try to start it like this as well:
/user/Flume/apache-flume-1.5.0-bin/bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n TwitterAgent
not sure if this makes a difference, but the server I'm working on is on amazon EC2 and where I believe you can't login as root but use sudo su instead, does that make a difference in the permissions? Sorry if this is trivial but i'm a linux rookie..
btw...great post too!
DeleteHi Praveen,
ReplyDeleteI am getting below log whenever i m starting flume.But i didn't get any twitte from twitter so according to below log flume is running or not?..
Could you please give me solution?
2014-09-02 12:22:23,322 (Twitter Stream consumer-1[Establishing connection]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:67)] X-Twitter-Client-URL: http://twitter4j.org/en/twitter4j-2.2.6.xml
2014-09-02 12:22:23,323 (Twitter Stream consumer-1[Establishing connection]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:67)] X-Twitter-Client: Twitter4J
2014-09-02 12:22:23,323 (Twitter Stream consumer-1[Establishing connection]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:67)] Accept-Encoding: gzip
2014-09-02 12:22:23,323 (Twitter Stream consumer-1[Establishing connection]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:67)] User-Agent: twitter4j http://twitter4j.org/ /2.2.6
2014-09-02 12:22:23,323 (Twitter Stream consumer-1[Establishing connection]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:67)] X-Twitter-Client-Version: 2.2.6
2014-09-02 12:22:23,323 (Twitter Stream consumer-1[Establishing connection]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:67)] Connection: close
(Twitter Stream consumer-1[Receiving stream]) [DEBUG - twitter4j.internal.logging.SLF4JLogger.debug(SLF4JLogger.java:67)] Twitter Stream consumer-1[Receiving stream]
ReplyDeleteException in thread "Twitter4J Async Dispatcher[0]" java.lang.NoSuchMethodError: twitter4j.json.JSONObjectType.determine(Ltwitter4j/internal/org/json/JSONObject;)Ltwitter4j/json/JSONObjectType;
at twitter4j.AbstractStreamImplementation$1.run(AbstractStreamImplementation.java:100)
at twitter4j.internal.async.ExecuteThread.run(DispatcherImpl.java:116)
2014-10-30 12:00:21,105 (conf-file-poller-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:126)] Checking file:conf/flume.conf for changes
solution for above problem?
I have the same problem. Have you solved?
DeleteThis comment has been removed by the author.
ReplyDeletesir i m trying to stream twitter data in hdfs but when i run flume agent although data is seen streaming on command line ,when i m checking namenode i m getting empty directory.Data is not going to hdfs pls help
ReplyDeletechange the search words like more general once good bad
Deletesir ..im trying my level best to create an hive external table but i m always getting this error ...pls help me sir ... i need to resolve this this issue soon ..
ReplyDeletehive> CREATE External TABLE dandanaka (
> id BIGINT,
> created_at STRING,
> source STRING,
> favorited BOOLEAN,
> retweet_count INT,
> retweeted_status STRUCT<
> text:STRING,
> user:STRUCT,
> retweet_count:INT>,
> entities STRUCT<
> urls:ARRAY>,
> usermentions:ARRAY>,
> hashtags:ARRAY>>,
> text STRING,
> user STRUCT<
> screen_name:STRING,
> name:STRING,
> friends_count:INT,
> followers_count:INT,
> statuses_count:INT,
> verified:BOOLEAN,
> utc_offset:INT,
> time_zone:STRING>,
> in_reply_to_screen_name STRING
> )
> ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.JsonSerde'
> LOCATION '/user/flume/tweets2';
FailedPredicateException(identifier,{useSQL11ReservedKeywordsForIdentifier()}?)
at org.apache.hadoop.hive.ql.parse.HiveParser_IdentifiersParser.identifier(HiveParser_IdentifiersParser.java:10924)
at org.apache.hadoop.hive.ql.parse.HiveParser.identifier(HiveParser.java:45850)
at org.apache.hadoop.hive.ql.parse.HiveParser.columnNameColonType(HiveParser.java:38211)
at org.apache.hadoop.hive.ql.parse.HiveParser.columnNameColonTypeList(HiveParser.java:36342)
at org.apache.hadoop.hive.ql.parse.HiveParser.structType(HiveParser.java:39707)
at org.apache.hadoop.hive.ql.parse.HiveParser.type(HiveParser.java:38655)
at org.apache.hadoop.hive.ql.parse.HiveParser.colType(HiveParser.java:38367)
at org.apache.hadoop.hive.ql.parse.HiveParser.columnNameType(HiveParser.java:38051)
at org.apache.hadoop.hive.ql.parse.HiveParser.columnNameTypeList(HiveParser.java:36203)
at org.apache.hadoop.hive.ql.parse.HiveParser.createTableStatement(HiveParser.java:5214)
at org.apache.hadoop.hive.ql.parse.HiveParser.ddlStatement(HiveParser.java:2640)
at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:1650)
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1109)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:202)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:166)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:396)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:308)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1122)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1170)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1059)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1049)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:213)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:165)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:736)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:681)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
FAILED: ParseException line 9:4 Failed to recognize predicate 'user'. Failed rule: 'identifier' in column specification
Is fluming twitter data to download twitter logs still available? or is it stopped? because i tried to flume twitter data today after long time with flume 1.4,java 1.6 but unable to download the twitter data
ReplyDeleteHello Everyone,
ReplyDeleteI am getting this error when running the select query.Can anybody help?
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing writable Objavro.schema�
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:185)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:450)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing writable Objavro.schema�
at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:501)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:176)
... 8 more
Caused by: org.apache.hadoop.hive.serde2.SerDeException: org.codehaus.jackson.JsonParseException: Unexpected character ('O' (code 79)): expected a valid value (number, String, array, object, 'true', 'false' or 'null')
at [Source: java.io.ByteArrayInputStream@649b97b1; line: 1, column: 2]
at org.apache.hive.hcatalog.data.JsonSerDe.deserialize(JsonSerDe.java:169)
at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.readRow(MapOperator.java:136)
at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.access$200(MapOperator.java:100)
at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:492)
... 9 more
Caused by: org.codehaus.jackson.JsonParseException: Unexpected character ('O' (code 79)): expected a valid value (number, String, array, object, 'true', 'false' or 'null')
at [Source: java.io.ByteArrayInputStream@649b97b1; line: 1, column: 2]
at org.codehaus.jackson.JsonParser._constructError(JsonParser.java:1433)
at org.codehaus.jackson.impl.JsonParserMinimalBase._reportError(JsonParserMinimalBase.java:521)
at org.codehaus.jackson.impl.JsonParserMinimalBase._reportUnexpectedChar(JsonParserMinimalBase.java:442)
at org.codehaus.jackson.impl.Utf8StreamParser._handleUnexpectedValue(Utf8StreamParser.java:2090)
at org.codehaus.jackson.impl.Utf8StreamParser._nextTokenNotInObject(Utf8StreamParser.java:606)
at org.codehaus.jackson.impl.Utf8StreamParser.nextToken(Utf8StreamParser.java:492)
at org.apache.hive.hcatalog.data.JsonSerDe.deserialize(JsonSerDe.java:158)
... 12 more
hi i am getting this error
Deleteplease help me if you find any solution.I am getting this error when creating external hive table for twitter data .
" Failed with exception java.io.IOException:org.apache.hadoop.hive.serde2.SerDeException: org.codehaus.jackson.JsonParseException: Unexpected character ('O' (code 79)): expected a valid value (number, String, array, object, 'true', 'false' or 'null')
at [Source: java.io.StringReader@6f6b3d33; line: 1, column: 2]
"
Hi,
ReplyDeletewhile creating the hive table i am getting following exception - ParseException line 9:6 Failed to recognize predicate 'user'. Failed rule: 'identifier' in column specification
when i change user oclumn name to usr it creates the table but processes no data. Can you please help?
Thanks Alot bro!!! you saved my life....
ReplyDeleteHi my hadoop user directory is not showing and twitter data. I am not getting any error while running following command
ReplyDeletebin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n TwitterAgent
It might not throw any error, but the problem is you are not giving the correct configuration directory path. The command should be as below
Deletebin/flume-ng agent --conf -f -Dflume.root.logger=DEBUG,console -n TwitterAgent
"flume configuration directory path" will usually be "/etc/flume-ng/conf"
"flume configuration file path" will usually be "/etc/flume-ng/conf/flume.conf"
and make sure you have created a directories "/user/flume/tweets" in hdfs.
Hello,
ReplyDeleteCan we define tweet rule while using "twitteragent.sources.twitter.keywords" property to fetch tweets specifically?
TIA
Hi Everyone ,
ReplyDeleteAm New to Hadoop, am getting the below error ,Could u please help me to sort the issue:-
hive> create table hashtags as select id as id,entities.hashtags.text as words from tweets;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = esak_20160823195256_135b0bdf-3fbb-4f69-8402-6f910afd0e9e
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
ENOENT: No such file or directory
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.chmodImpl(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.chmod(NativeIO.java:230)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:724)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:502)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:600)
at org.apache.hadoop.mapreduce.JobResourceUploader.uploadFiles(JobResourceUploader.java:94)
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:95)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:190)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:575)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:570)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:570)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:561)
at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.execute(ExecDriver.java:433)
at org.apache.hadoop.hive.ql.exec.mr.MapRedTask.execute(MapRedTask.java:138)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:197)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:100)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1858)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1562)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1313)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1084)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1072)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:232)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:183)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:399)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:776)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:714)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:641)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Job Submission failed with exception 'org.apache.hadoop.io.nativeio.NativeIOException(No such file or directory)'
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. No such file or directory
please Help me to solve this.............
Is fluming twitter data to download twitter logs still available? or is it stopped?
ReplyDeleteC:\>curl http://stream.twitter.com 443
curl: (7) Failed to connect to stream.twitter.com port 80: Timed out
curl: (6) Could not resolve host: 443
can anyone explain.. ?
Is fluming twitter data to download twitter logs still available? or is it stopped?
ReplyDeleteC:\Users\abhilash_mohabey>curl http://stream.twitter.com 443
curl: (7) Failed to connect to stream.twitter.com port 80: Timed out
curl: (6) Could not resolve host: 443
can anybody help..?
Hi,
ReplyDeleteAs per the above steps, I have fetched the Twitter data into HDFS and created a table in Hive. I am unable to fetch the data into Hive Table. Facing the following error. Please help me out of it.
hive> SELECT t.retweeted_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name as retweeted_screen_name, retweeted_status.text, max(retweet_count) as retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweeted_screen_name ORDER BY total_retweets DESC LIMIT 10;
Query ID = cloudera_20161031070909_33a45a44-9a7b-49e8-a754-e694ff554d67
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
java.lang.StackOverflowError
at java.net.URI$Parser.checkChars(URI.java:3000)
at java.net.URI$Parser.parseHierarchical(URI.java:3086)
at java.net.URI$Parser.parse(URI.java:3044)
at java.net.URI.(URI.java:595)
at java.net.URI.create(URI.java:857)
at org.apache.hadoop.fs.FileContext.getFileContext(FileContext.java:473)
at org.apache.hadoop.fs.FileContext.getFileContext(FileContext.java:447)
at org.apache.hadoop.fs.FileContext.getFileContext(FileContext.java:473)
at org.apache.hadoop.fs.FileContext.getFileContext(FileContext.java:447)
at org.apache.hadoop.fs.FileContext.getFileContext(FileContext.java:473)
at org.apache.hadoop.fs.FileContext.getFileContext(FileContext.java:447)
FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. null
I am facing the same error . If you have figured out how to fix this , please let me know
DeleteI have the same error. If you have figured out how to fix it, can you please tell me.
ReplyDeleteWhile running select * query from data loaded in hive, I am geting result of 1 tweet only when using limit 1. But if I run general select query without any limit, then I get error :
ReplyDeleteFailed with exception java.io.IOException:org.apache.avro.AvroRuntimeException: java.io.IOException: Block size invalid or too large for this implementation: -40
Suggest solution
Hi i followed all the steps as per your post but i am facing errors.. anyone can help me??
ReplyDeleteINFO twitter4j.TwitterStreamImpl: 404:The URI requested is invalid or the resource requested, such as a user, does not exist.
Unknown URL. See Twitter Streaming API documentation at http://dev.twitter.com/pages/streaming_api
Hi
ReplyDeleteI'm getting the below error, while executing this query,
SELECT t.retweeted_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name as retweeted_screen_name, retweeted_status.text, max(retweet_count) as retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweeted_screen_name ORDER BY total_retweets DESC LIMIT 10;
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2017-10-05 04:52:12,029 Stage-1 map = 0%, reduce = 0%
2017-10-05 04:52:29,965 Stage-1 map = 100%, reduce = 100%
Ended Job = job_1506695677341_0040 with errors
Error during job, obtaining debugging information...
Examining task ID: task_1506695677341_0040_m_000000 (and more) from job job_1506695677341_0040
Task with the most failures(4):
-----
Task ID:
task_1506695677341_0040_m_000000
URL:
http://0.0.0.0:8088/taskdetails.jsp?jobid=job_1506695677341_0040&tipid=task_1506695677341_0040_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:109)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:75)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:446)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:106)
... 9 more
Caused by: java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:109)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:75)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133)
at org.apache.hadoop.mapred.MapRunner.configure(MapRunner.java:38)
... 14 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:106)
... 17 more
Caused by: java.lang.RuntimeException: Map operator initialization failed
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.configure(ExecMapper.java:157)
... 22 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassNotFoundException: Class com.cloudera.hive.serde.JSONSerDe not found
at org.apache.hadoop.hive.ql.exec.MapOperator.getConvertedOI(MapOperator.java:334)
at org.apache.hadoop.hive.ql.exec.MapOperator.setChildren(MapOperator.java:352)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.configure(ExecMapper.java:126)
... 22 more
Caused by: java.lang.ClassNotFoundException: Class com.cloudera.hive.serde.JSONSerDe not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:195)
Could you please tel me, what is the issue
I want to store tweets in KAfka Topic. what changes are required can anyone suggest ? I am new to Hadoop World
ReplyDeletei am having problem with creating table in hive
ReplyDeleteI Have added the jar as mentioned above
and in create table command
it shows the error
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org/apache/hadoop/hive/serde2/SerDe
Hello,
ReplyDeleteI have successfully fetch twitter data using flume and stored it in HDFS , but I was using pig for further analysis and in that I am not able to clean the data because the tweets recorded are in arabic chinese and some other languages including english , but the problem I face here is I am not able to get only english tweets