As I mentioned earlier getting started with Hama is very easier to use for those who are familiar with Hadoop. Much of the ideas and code have been borrowed from Hadoop.
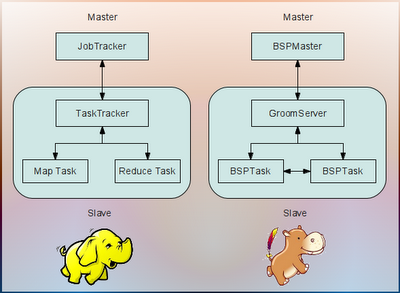
Hama also follows master/slave pattern. Above picture conveys the mapping between Hadoop and Hama. A JobTracker maps to a BSPMaster, TaskTracker maps to a GroomServer and Map/Reduce task maps to a BSPTask.
The major difference between Hadoop and Hama is while map/reduce tasks can't communicate with each other, BSPTask can communicate to each other. So, when a job requires multiple iterations (as in the case of graph processing) the data between iterations has to be persisted and read back when MapReduce (Hadoop) is used. This is not the case with BSP (Hama) as the tasks can communicate with each other. This leads to better efficiency as the overhead of disk writing and reading is avoided.
Here are some more details about the Hama architecture.

Hama also follows master/slave pattern. Above picture conveys the mapping between Hadoop and Hama. A JobTracker maps to a BSPMaster, TaskTracker maps to a GroomServer and Map/Reduce task maps to a BSPTask.
The major difference between Hadoop and Hama is while map/reduce tasks can't communicate with each other, BSPTask can communicate to each other. So, when a job requires multiple iterations (as in the case of graph processing) the data between iterations has to be persisted and read back when MapReduce (Hadoop) is used. This is not the case with BSP (Hama) as the tasks can communicate with each other. This leads to better efficiency as the overhead of disk writing and reading is avoided.
Here are some more details about the Hama architecture.
No comments:
Post a Comment