In the previous blog, we looked at on converting the CSV format into Parquet format using Hive. It was a matter of creating a regular table, map it to the CSV data and finally move the data from the regular table to the Parquet table using the Insert Overwrite syntax. In this blog we will look at how to do the same thing with Spark using the dataframes feature.

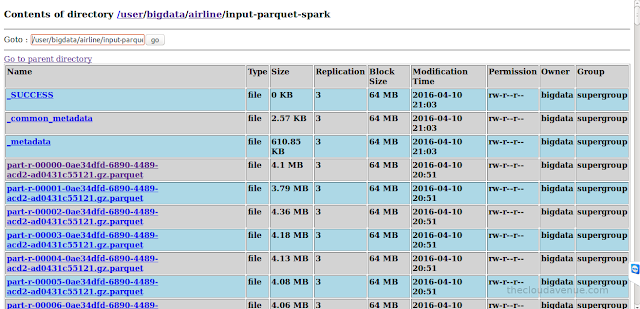
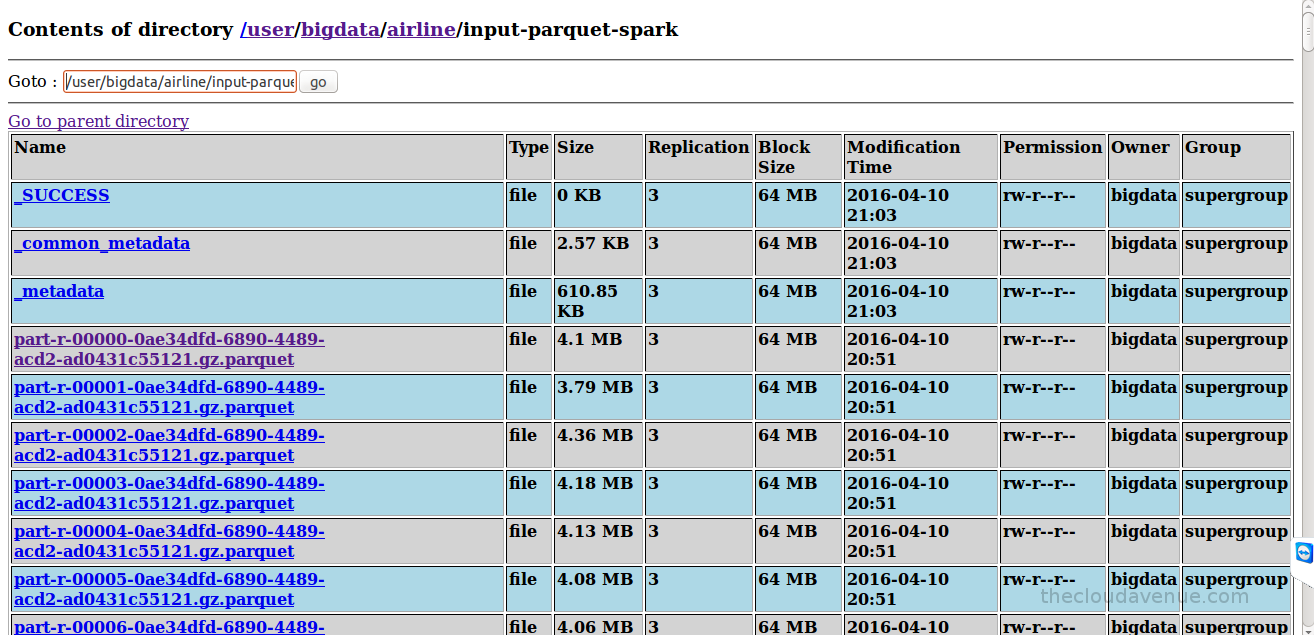
As seen in the below HDFS console, the number of Parquet files created by Spark were more than the number of files created by Hive and also smaller is size. This is not really efficient as HDFS has not be created to store smaller files. Here is an article from Cloudera on the same. Spark converted each block into a separate file in Parquet, but Hive combined multiple blocks into a single Parquet file. These are pros and cons of the way Hive and Spark have created the Parquet files which would be discussed in an upcoming blog.
Below is the comparison of the time taken and the size for both Hive and Spark. Note that these are got by using the out of the box setting with Hive and Spark and can be further fine tuned. The difference is the size if the default compression codes set in Hive and Spark.

from pyspark import SparkConf
from pyspark import SparkContext
from pyspark.sql import SQLContext
conf = SparkConf().setMaster("spark://bigdata-server:7077")
sc = SparkContext(conf=conf, appName="flightDataAnalysis")
sqlContext = SQLContext(sc)
#converts a line into tuple
def airlineTuple(line):
values = line.split(",")
return (
values[0], values[1], values[2], values[3], values[4], values[5], values[6], values[7], values[8], values[9],
values[10], values[11], values[12], values[13], values[14], values[15], values[16], values[17], values[18], values[19],
values[20], values[21], values[22], values[23], values[24], values[25], values[26], values[27], values[28])
#load the airline data and covert into an RDD of tuples
lines = sc.textFile("hdfs://localhost:9000/user/bigdata/airline/input").map(airlineTuple)
#convert the rdd into a dataframe
df = sqlContext.createDataFrame(lines, ['Year', 'Month', 'DayofMonth', 'DayOfWeek', 'DepTime', 'CRSDepTime', 'ArrTime',
'CRSArrTime', 'UniqueCarrier', 'FlightNum', 'TailNum', 'ActualElapsedTime',
'CRSElapsedTime', 'AirTime', 'ArrDelay', 'DepDelay', 'Origin', 'Dest',
'Distance', 'TaxiIn', 'TaxiOut', 'Cancelled', 'CancellationCode', 'Diverted',
'CarrierDelay', 'WeatherDelay', 'NASDelay', 'SecurityDelay',
'LateAircraftDelay'])
#save the dataframe as a parquet file in HDFS
df.write.parquet("hdfs://localhost:9000/user/bigdata/airline/input-parquet-spark")
Spark took a bit more time to convert the CSV into Parquet files, but Parquet files created by Spark were a bit more compressed when compared to Hive. This is because Spark uses gzip and Hive uses snappy for Parquet compression. The spark.sql.parquet.compression.codec property can be used to change the Spark parquet compression codec.As seen in the below HDFS console, the number of Parquet files created by Spark were more than the number of files created by Hive and also smaller is size. This is not really efficient as HDFS has not be created to store smaller files. Here is an article from Cloudera on the same. Spark converted each block into a separate file in Parquet, but Hive combined multiple blocks into a single Parquet file. These are pros and cons of the way Hive and Spark have created the Parquet files which would be discussed in an upcoming blog.
Below is the comparison of the time taken and the size for both Hive and Spark. Note that these are got by using the out of the box setting with Hive and Spark and can be further fine tuned. The difference is the size if the default compression codes set in Hive and Spark.

No comments:
Post a Comment