Scheduler in Hadoop is for sharing the cluster between different jobs, users for better utilization of the cluster resources. Also, without a scheduler a Hadoop job might consume all the resources in the cluster and other jobs have to wait for it to complete. With scheduler jobs can execute in parallel consuming a part of cluster.
Hadoop has a pluggable interface for schedulers. All implementations of the scheduler should extend the abstract class TaskScheduler and the scheduler class should be specified in the `mapreduce.jobtracker.taskscheduler` property (defaults to org.apache.hadoop.mapred.JobQueueTaskScheduler). The Capacity Scheduler, Fair Scheduler and other scheduler implementations are shipped with Hadoop.
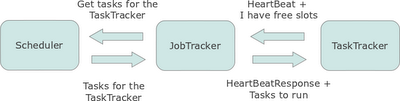
The TaskTracker sends a heart beat (TaskTracker#transmitHeartBeat) to the JobTracker at regular intervals, in the heart beat it also indicates that it can take new tasks for execution. Then the JobTracker (JobTracker#heartbeat) consults the Scheduler (TaskScheduler#assignTasks) to assign tasks to the TaskTracker and sends the list of tasks as part of the HeartbeatResponse to the TaskTracker.
Hadoop has a pluggable interface for schedulers. All implementations of the scheduler should extend the abstract class TaskScheduler and the scheduler class should be specified in the `mapreduce.jobtracker.taskscheduler` property (defaults to org.apache.hadoop.mapred.JobQueueTaskScheduler). The Capacity Scheduler, Fair Scheduler and other scheduler implementations are shipped with Hadoop.
The TaskTracker sends a heart beat (TaskTracker#transmitHeartBeat) to the JobTracker at regular intervals, in the heart beat it also indicates that it can take new tasks for execution. Then the JobTracker (JobTracker#heartbeat) consults the Scheduler (TaskScheduler#assignTasks) to assign tasks to the TaskTracker and sends the list of tasks as part of the HeartbeatResponse to the TaskTracker.

No comments:
Post a Comment